The Ultimate Guide To Knowing What The Heck You're Talking About
The destruction of imposter syndrome...





HTML
CSS
JavaScript

Alright, so HTML, CSS, and JavaScript are like the ingredients for a cake. You know how when you're making a cake, you need certain ingredients like flour, sugar, and eggs to make the cake? HTML, CSS, and JavaScript are like those ingredients, but for making websites.
HTML stands for Hypertext Markup Language, it's like the flour in the cake recipe, it's the structure and content of the website. It's the backbone of a website, it tells the browser what the website is about, what the different parts of the website are, and how they are organized.
CSS stands for Cascading Style Sheets, it's like the sugar in the cake recipe, it's the design and layout of the website. It's used to control the look and feel of the website, such as the colors, fonts, and spacing.
JavaScript is like the eggs in the cake recipe, it's the interactive part of the website. It's a programming language that allows you to add interactivity and dynamic behavior to the website, such as dropdown menus, pop-ups and animations.
Together, HTML, CSS, and JavaScript are used to create the overall look and feel of a website, and make it interactive for users.
So, in short, HTML, CSS, and JavaScript are like the ingredients for a cake, HTML stands for Hypertext Markup Language, it's like the flour in the cake recipe, it's the structure and content of the website, CSS stands for Cascading Style Sheets, it's like the sugar in the cake recipe, it's the design and layout of the website, JavaScript is like the eggs in the cake recipe, it's the interactive part of the website, Together, HTML, CSS, and JavaScript are used to create the overall look and feel of a website, and make it interactive for users.
JS also has an event driven architecture.
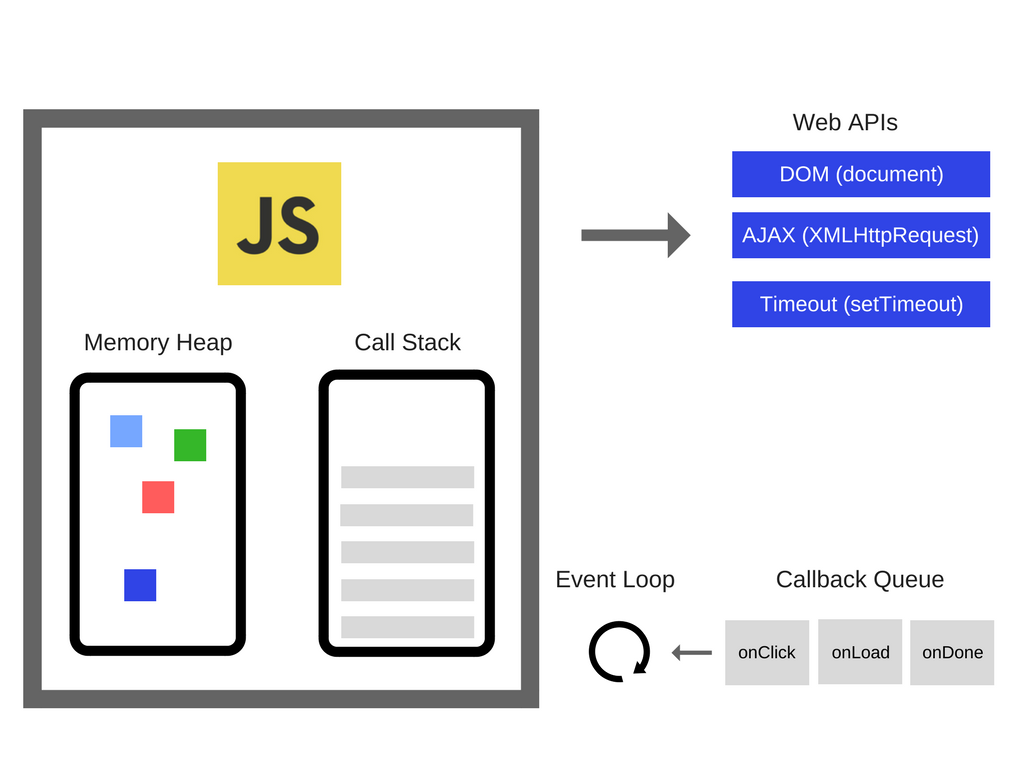
JavaScript's event-driven architecture is a programming model in which the flow of the program is determined by events such as user actions, sensor outputs, or messages from other programs. In this architecture, the program sets up event listeners that wait for specific events to occur, and then triggers a callback function to handle the event when it occurs.
An analogy for this could be a traffic light system at an intersection. The traffic light system is constantly listening for the various events such as cars approaching the intersection, pedestrians crossing the street, and the timer for the lights to change. Once an event is detected, the traffic light system triggers the appropriate action, such as changing the lights or activating the walk signal for pedestrians.
This type of architecture allows for a non-blocking and asynchronous flow of the program, meaning that the program can continue to execute other tasks while waiting for events to occur, rather than being blocked or held up by a single task. This can greatly improve the performance and responsiveness of the program.
This is also why Brendan Eichs is a genius... literally.
Node JS
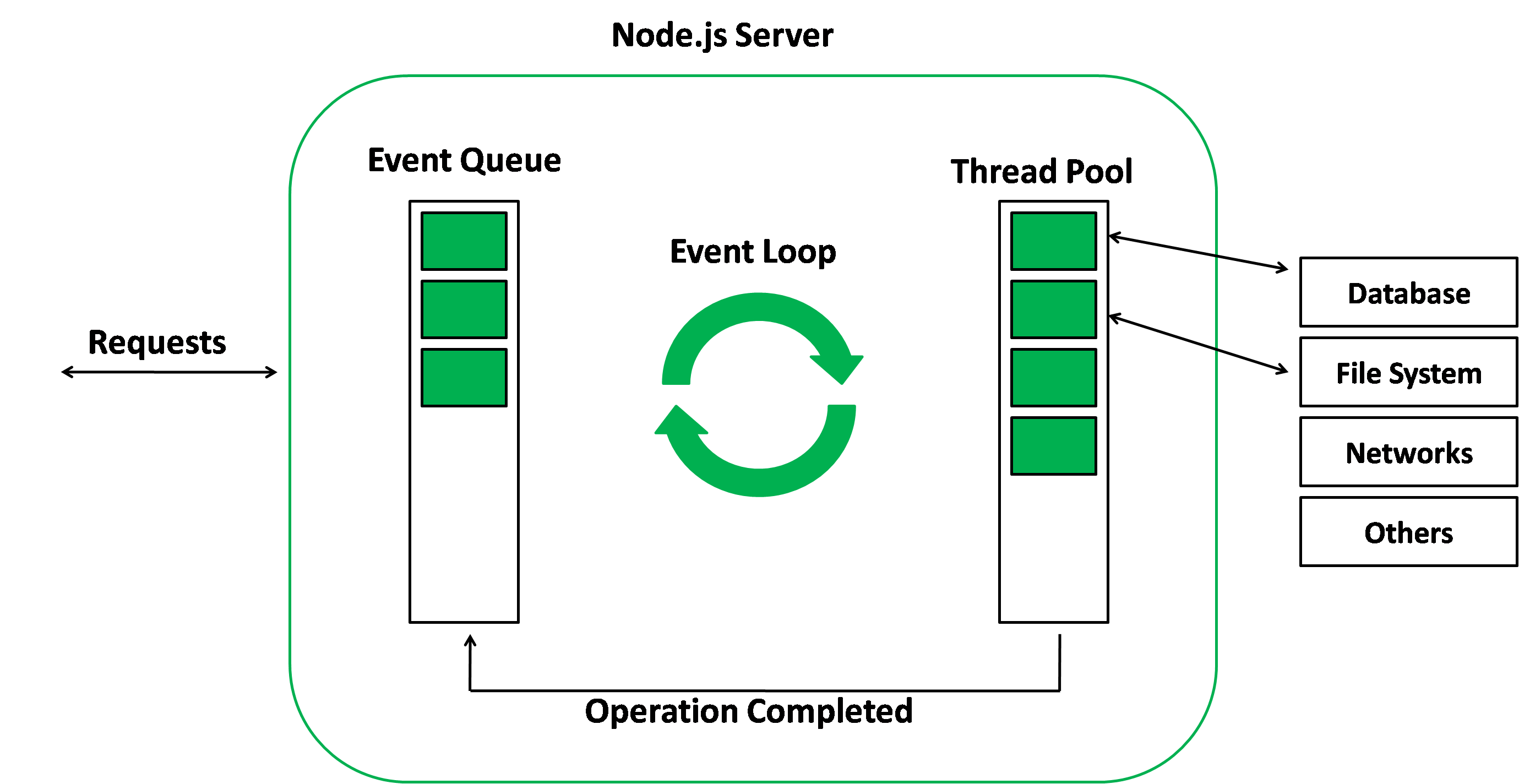
Node.js is a JavaScript runtime built on Chrome's V8 JavaScript engine. It allows developers to run JavaScript on the server side, which was previously only possible on the client side (in web browsers). One of the key characteristics of Node.js is its single-threaded architecture.
The single-threaded architecture of Node.js means that it only uses one core of a computer's processor, and all operations are performed sequentially on a single thread. This means that all incoming requests are handled one at a time, and that there is no parallel processing of requests. While this may seem like a limitation, it can actually be beneficial in certain situations.
One benefit of the single-threaded architecture is that it can be more efficient in terms of memory usage, as there are no separate threads to manage and synchronize. Additionally, it simplifies the programming model, as developers do not have to worry about managing multiple threads and ensuring that they do not conflict with each other.
Another benefit of the single-threaded architecture is that it allows Node.js to handle a large number of concurrent connections. Instead of spawning a separate thread for each connection, which can quickly consume all available resources, Node.js uses an event loop to handle multiple connections on a single thread. This allows it to handle a large number of connections with relatively low resources.
However, it's important to note that this single-threaded approach may not be suitable for all types of applications and workloads. Applications that require heavy computation or that need to perform multiple tasks simultaneously may be better suited for a multi-threaded architecture.
In summary, Node.js's single-threaded architecture is a design choice that allows it to be more efficient in terms of memory usage and simplifies the programming model. It also allows Node.js to handle a large number of concurrent connections. However, it may not be suitable for all types of applications and workloads.
CRUD:
CRUD is like a to-do list. You can Create a new task, Read the tasks you already have, Update a task you've already created, and Delete a task you no longer need. It's a basic set of operations that allows you to manage data in a database.
REST:
REST is like a menu at a restaurant. Just like how a menu lists different dishes available at the restaurant, REST defines different endpoints (or "dishes") that are available in a web service. Each endpoint represents a specific resource that can be accessed and manipulated using standard HTTP methods (GET, POST, PUT, DELETE).
MVC:
MVC is like a chef in a kitchen. The chef separates the different aspects of preparing a meal (the model, the view, and the controller) and assigns specific tasks to each aspect. In software development, the model represents the data, the view is the user interface, and the controller handles the logic and communication between the model and the view.
Server Side Rendering:
Server-side rendering is like a chef preparing a dish in the kitchen before bringing it out to the customers. The chef (server) prepares the dish (HTML) and then serves it to the customer (browser) who requested it. With server-side rendering, the server generates the HTML for a web page and sends it to the browser, as opposed to the browser generating the HTML.
Client Side Rendering:
Client-side rendering is like a customer ordering a dish at a restaurant and then being able to customize it themselves. The customer (browser) receives the basic ingredients (data) and then prepares the dish (HTML) to their liking. With client-side rendering, the browser receives the data and generates the HTML, as opposed to the server generating the HTML.
Consuming an API:
Consuming an API is like ordering food at a restaurant. Just like how you would order a dish from a menu, you make a request to an API to retrieve or manipulate data. The API then sends back the appropriate response, just like a server bringing your dish to the table.
Seperation of Concerns:
MVC, Component Driven Development and RESTFUL Routing are all examples of seperation of concerns
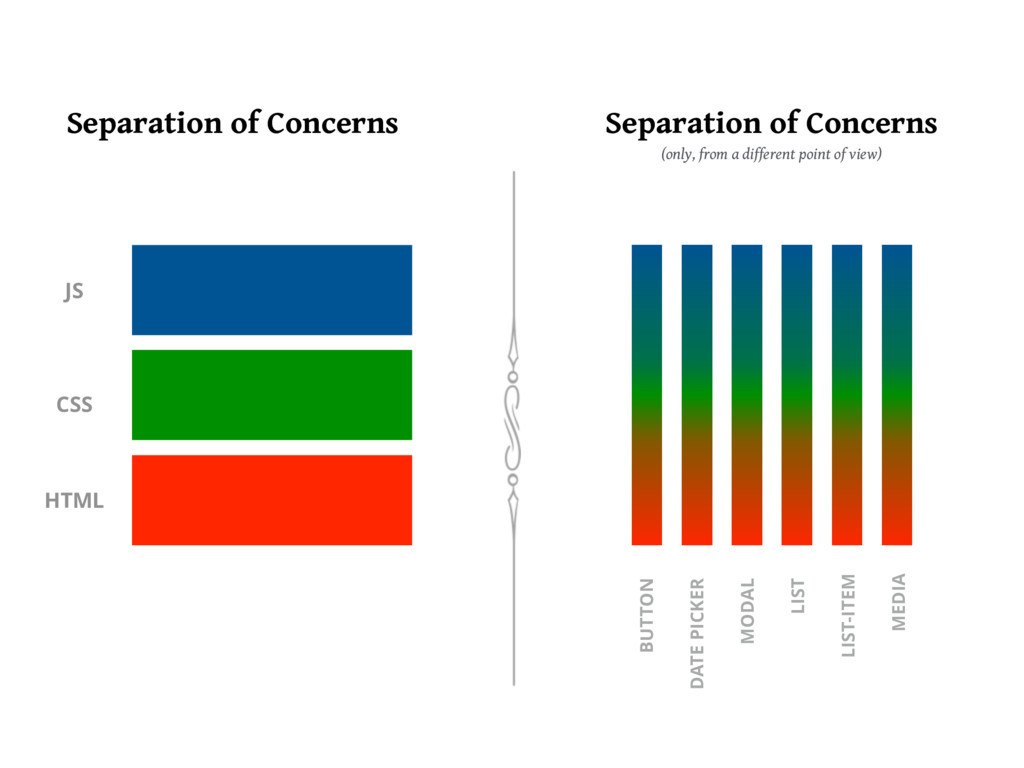
Separation of concerns is like a chef having different stations in the kitchen. Each station is responsible for a specific task, such as preparing vegetables, grilling meats, etc. In software development, separation of concerns refers to dividing the code into different sections, each responsible for a specific task, such as handling user input, managing data, etc.
Component Driven Development
Component-driven development is like building with LEGOs. Each LEGO piece represents a component, and you can use different components to build different things. Each component has its own function and purpose, and you can easily swap out or reuse components to create different designs. In software development, components are reusable pieces of code that can be used to build different parts of a website or application. By breaking down a website or application into smaller, reusable components, developers can easily build and maintain complex projects. Additionally, component-driven development makes it easy to update and change specific parts of an application without affecting the entire system. It also allows for better collaboration between developers as each component can be worked on by different team members and integrated later. So, in short, component-driven development is like building with LEGOs, it allows for the creation of reusable and modular code that can be easily integrated and updated in a complex project.
How we seperated concerns in the MERN Project
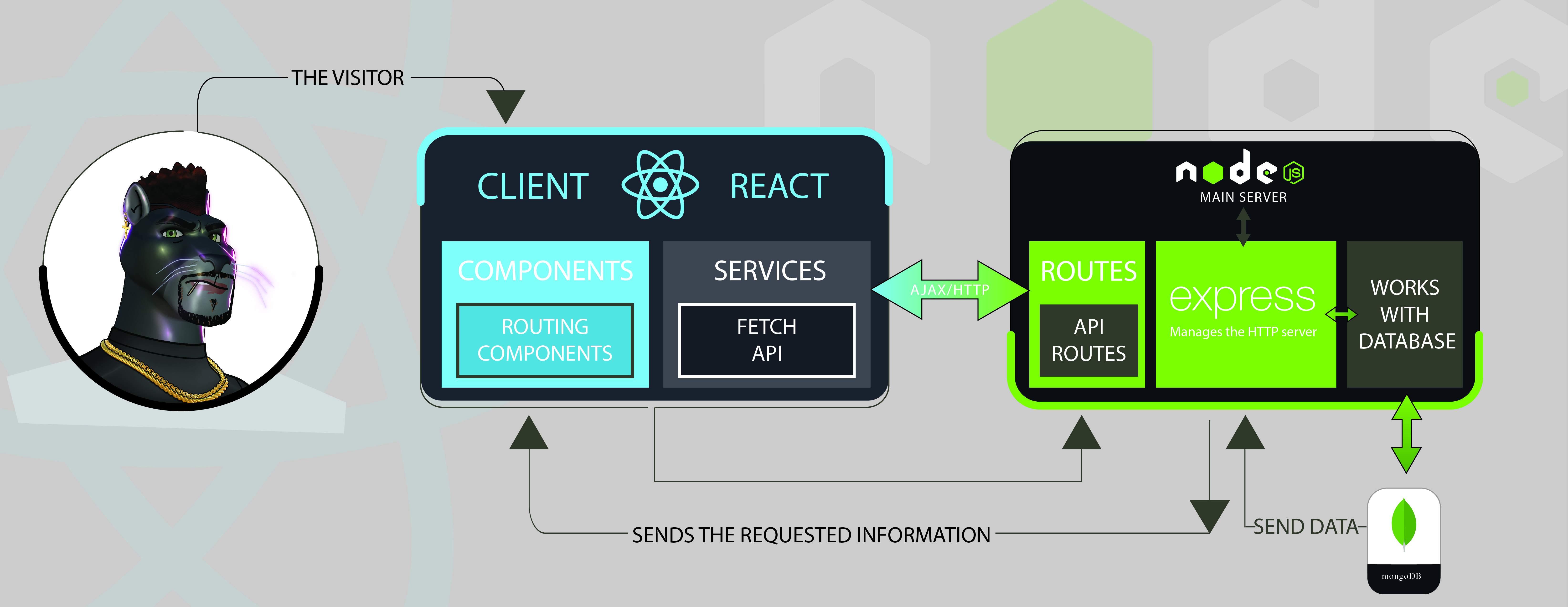
Client-Server Model
The client-server model is similar to a game of chess where the client, like the player, makes requests and the server, like the opponent, receives requests and responds, both parties are necessary for the game to progress.
IP Address
An IP address is a unique set of numbers that acts as a digital address for devices on the internet, similar to a street address. It is used to identify and locate devices on a network, and allows them to communicate with each other. There are two types of IP addresses, private and public, with private being used within a network and public being used for external communication.
PORT
A port on a computer is like a doorway that provides access to specific services or applications running on the device. Each port corresponds to a specific function and directs different types of internet traffic to the appropriate service or application. For example, port 80 is used for accessing the web, port 25 is used for email, and port 443 is used for secure connections. In summary, a port is a way for a computer to know where to send and receive data from, it is a doorway to a specific service or application on the device.
DNS
DNS (Domain Name System) is like a personal navigator for the internet, similar to a friend who knows all the shortcuts in the neighborhood. When a user types a website name into their browser, the computer doesn't know where to find it. It requests help from a DNS server, which acts like a translator, and converts the website name into an IP address that the computer can understand and use to locate the website. In summary, DNS functions like the GPS of the internet, it helps users find the right website by translating the website name into an IP address that the computer can use to locate it.
IP Packets
IP packets are like packages used to send data across the internet. The data is broken down into small chunks called packets, each containing information about where it is coming from and where it is going. These packets are sent out on the internet, like a package being shipped, and they make their way to the destination. Along the way, they are checked for errors such as incorrect addressing or damage during transit. When all the packets arrive at the destination, they are reassembled back into the original message, ensuring that the data is received in the correct order and that nothing is lost during transmission.
IP TCP HTTP
In summary, IP (Internet Protocol) is a unique set of numbers that acts as a digital address for devices on the internet, similar to a street address. It is used to identify and locate devices on a network and allows them to communicate with each other. TCP (Transmission Control Protocol) is responsible for ensuring that data is transmitted to the correct destination and in the correct order. HTTP (Hypertext Transfer Protocol) is the standard language used for transferring data on the web and is used by browsers and websites to communicate with each other. HTTPS (Hypertext Transfer Protocol Secure) is an enhanced version of HTTP that encrypts data in transit, providing an added layer of security for online communications. Together, these protocols allow devices to communicate and access information on the internet.
Databse
A database is a collection of organized and stored information that can be easily accessed and understood by computers. It functions like a large notebook where important information is recorded and stored in one place. This information can be searched and accessed, much like flipping through a notebook to find a specific note or contact. Databases are used to store and organize information, making it easily accessible for computers.
Disk, Memory & Persistent Storage
The disk storage in a computer is similar to a physical closet, where long-term storage of files, music, videos, and other data are kept. Memory, on the other hand, can be thought of as pockets, where the computer keeps the files and information that it needs to access immediately. When working on a document, for example, it is saved to the disk storage, similar to placing it in a closet. But when it is opened for editing, it is loaded into memory, similar to taking it out of a closet and placing it in a pocket. This organization of information allows the computer to quickly access the files it needs at any given time.
Persistent storage, in a computer, is similar to keeping items in a attic. Just like how you store old toys or other items in an attic and can retrieve them later, persistent storage allows for data to be saved and retrieved even after the computer is turned off or rebooted. This type of storage ensures that important files, settings and preferences are retained, even in the event of a power outage or computer restart. Persistent storage serves as a safe place to store important information, making it accessible even after the computer has been turned off or rebooted.
Blob Storage
Blob storage can be thought of as a digital warehouse. Just like how a warehouse stores and organizes physical goods, blob storage stores and organizes large amounts of digital data such as video, audio, and image files. The data is stored in "blobs" (binary large objects) and can be easily accessed, retrieved, and managed. Each blob can be labeled and categorized, similar to how goods in a warehouse are labeled and organized on shelves. Blob storage provides a secure and efficient way to store and access large amounts of digital data, much like a warehouse does for physical goods. Amazon s3, cloudinary, google cloud all provide blob storage very few places setup their own blob storage.
Latency and Throughput
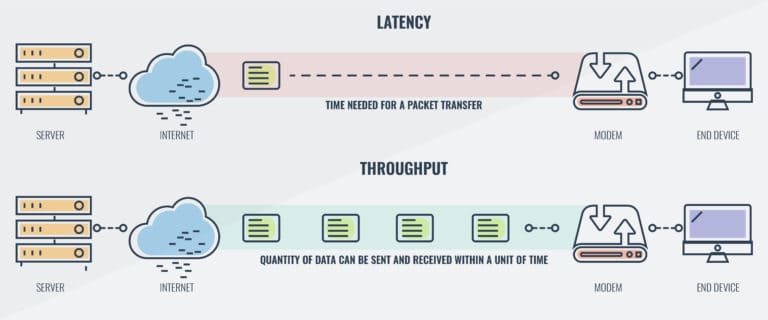
Latency is the delay in the time it takes for a message to be sent and received over the internet. It can be thought of as waiting for a bus to arrive at a stop, where low latency is equivalent to the bus arriving on time and high latency is equivalent to the bus being late. This delay can have an impact on internet performance, particularly for real-time applications such as video streaming and online gaming.
Throughput is a measure of the amount of data that can be transferred over a network connection in a specific period of time. It is similar to the concept of the capacity of a bus, in that a high throughput allows for more data to be transferred quickly, just as an empty bus allows for more passengers to board. Conversely, a low throughput results in a slower transfer of data, similar to a crowded bus that can't take on any more passengers. It is an important factor to consider when evaluating the performance of internet connections, particularly for high-bandwidth applications such as streaming and online gaming.
Availability, High Availability, Nines, Redundancy, SLA, SLO
Availability is like a reliable friend who is always there when you need them. Like how your friend is always available to hang out or help you out, availability in software systems refers to how often the system is up and running, ready to be used.
High availability is like having a friend who is not only reliable, but always on time and ready to go. Similarly, high availability in software systems refers to the measure of how often the system is up and running, ready to be used, with a higher percentage of uptime than regular availability.
Nines are like a grade for your friend's reliability. If they are always there for you, they get a high grade like an A+. If they're sometimes late or unavailable, they get a lower grade like a B-. In software systems, nines are a measure of the system's uptime, with 99.9% being a grade, "three nines".
Redundancy is like having a backup friend. If your first friend can't make it, you have a plan B to rely on. Similarly, redundancy in software systems refers to having backup systems or components in place, so that if one fails, the other can take over and keep the system running.
SLA (Service Level Agreement) is like a contract with your friend. You agree on certain things, like how often he'll be there, and what happens if he can't make it. It's the same thing with software systems, an SLA is a contract that outlines the level of service that the system will provide and what happens if it doesn't meet that level of service.
SLO (Service Level Objective) is like a goal for your friend's reliability. You set a goal for him to be there a certain percentage of the time, and you work towards that goal. It's the same thing with software systems, an SLO is a goal for the system's uptime, and it's used to measure and improve the system's performance.
So, in short:
- Availability is the measure of how often the system is up and running, ready to be used.
- High Availability is the measure of how often the system is up and running, ready to be used, with a higher percentage of uptime.
- Nines is a measure of the system's uptime, with 99.9% uptime being like a grade we could have 99.9999% or
six ninesor 99.99%four nines. - Redundancy is having backup systems or components in place, so that if one fails, the other can take over, and keep the system running.
- SLA (Service Level Agreement) is a contract that outlines the level of service that the system will provide and what happens if it doesn't meet that level of service.
- SLO (Service Level Objective) is a goal for the system's uptime, and it's used to measure and improve the system's performance.
Cache
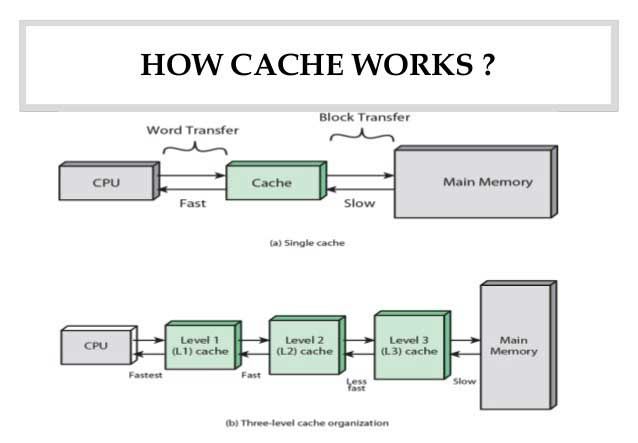
A cache, it's like a stash. You know how when you're a kid and you got a spot where you hide your toys and snacks, so you can grab them quickly when you need them? A cache is like that, but for computers.
A cache is a temporary storage area where a computer or a network device stores frequently accessed data. It's like a stash where the computer can quickly grab the data it needs without having to go through the whole process of fetching it again. It's a way of speeding up the access to data by keeping a copy of it in a location that is faster to access than the original source.
For example, when you visit a website, your browser stores a copy of the webpage in the cache, so the next time you visit the same website, the browser can grab the cached version, which loads faster than fetching the page again.
So, in short, a cache is like a stash, it's a temporary storage area where a computer or a network device stores frequently accessed data, it's a way of speeding up the access to data by keeping a copy of it in a location that is faster to access than the original source.
Cache Hit
A cache hit, it's like when you go to your stash and find exactly what you're looking for. You know when you go to your stash and the toy or snack you wanted is right there, waiting for you? A cache hit is like that, but for computers.
A cache hit is when a computer or a network device looks for data in its cache, and it finds the data it needs. It's like when you go to your stash and you find the toy or snack you wanted. It's a quick and efficient way to access the data because the computer doesn't have to go through the process of fetching it again from the original source.
For example, when you visit a website, your browser looks for the webpage in its cache. If it finds the cached version of the page, it's a cache hit, and the page loads faster.
So, in short, a cache hit is like when you go to your stash and find exactly what you're looking for, it's when a computer or a network device looks for data in its cache, and it finds the data it needs, it's a quick and efficient way to access the data because the computer doesn't have to go through the process of fetching it again from the original source.
Cache Miss
A cache miss, it's like when you go to your stash and the toy or snack you wanted isn't there. You know when you go to your stash and the toy or snack you wanted is not there? A cache miss is like that, but for computers.
A cache miss is when a computer or a network device looks for data in its cache, but it doesn't find the data it needs. It's like when you go to your stash and you don't find the toy or snack you wanted. It happens when the data the computer is looking for is not in the cache, so the computer has to go through the process of fetching it again from the original source.
For example, when you visit a website, your browser looks for the webpage in its cache. If it doesn't find the cached version of the page, it's a cache miss, and the browser has to fetch the page again from the original source.
So, in short, a cache miss is like when you go to your stash and the toy or snack you wanted isn't there, it's when a computer or a network device looks for data in its cache, but it doesn't find the data it needs, it happens when the data the computer is looking for is not in the cache, so the computer has to go through the process of fetching it again from the original source.
Cache Eviction Policy
Alright, so a cache eviction policy, it's like how you decide what to keep and what to throw away in your stash. You know how when your stash gets full, you have to decide what to keep and what to throw away? A cache eviction policy is like that, but for computers.
A cache eviction policy is a set of rules that a computer or a network device uses to decide which data to keep in its cache and which data to remove. It's like how you decide what to keep and what to throw away in your stash.
For example, a common cache eviction policy is the Least Recently Used (LRU) policy, it removes the data that hasn't been used for the longest time, it's like when you haven't played with a toy for a while, you might decide to throw it away or give it to someone else. Another example is the Least Frequently Used (LFU) policy, it removes the data that has been accessed less often, it's like when you haven't eaten a snack for a while, you might decide to throw it away or give it to someone else.
So, in short, a cache eviction policy is like how you decide what to keep and what to throw away in your stash, it's a set of rules that a computer or a network device uses to decide which data to keep in its cache and which data to remove.
Content Delivery Network
Alright, so a Content Delivery Network (CDN) is like a team of helpers for your delivery business. You know how when you run a delivery business, you got a team of helpers that work together to get the packages to the customers on time? A CDN is like that, but for the internet.
A CDN is a network of servers that are strategically placed around the world. These servers work together to deliver content, like web pages, images, videos, and other files, to users faster and more efficiently. It's like having a team of helpers that work together to get the packages to the customers on time.
For example, when a user in New York wants to access a website hosted in California, instead of the user connecting to the website's main server in California, the user will connect to a server in a nearby location, like New York, that is part of the CDN. This helps to reduce the time it takes to access the website, and it also helps to reduce the load on the main server.
So, in short, a Content Delivery Network (CDN) is like a team of helpers for your delivery business, it's a network of servers that are strategically placed around the world, these servers work together to deliver content, like web pages, images, videos, and other files, to users faster and more efficiently.
Proxy
Forward Proxy
Reverse Proxy
Nginx
Load Balancer

A proxy is like a middleman. You know how when you want to buy something, but you don't want to deal with the seller directly, so you get someone else to do it for you? A proxy is like that, but for the internet.
A proxy is a server or a software that acts as an intermediary between a client and a server. It can be used to hide the client's identity, to filter traffic, or to cache content. It's like a middleman that helps to protect the client and the server from each other.
A forward proxy is like a middleman that helps you buy something. It's a proxy that sits in front of the client, and it helps the client to access the internet. It can be used to hide the client's identity, to filter traffic, or to cache content.
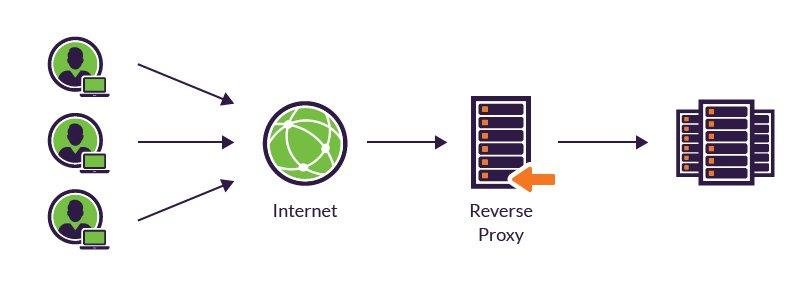
A reverse proxy is like a middleman that helps the seller. It sits in front of the server, and it helps the server to handle the incoming requests. It can be used to hide the server's identity, to distribute the load, or to cache content.
Nginx is a popular web server software that can be used as a proxy, a forward proxy, a reverse proxy, or a load balancer. It's like a middleman that can do multiple jobs at once.
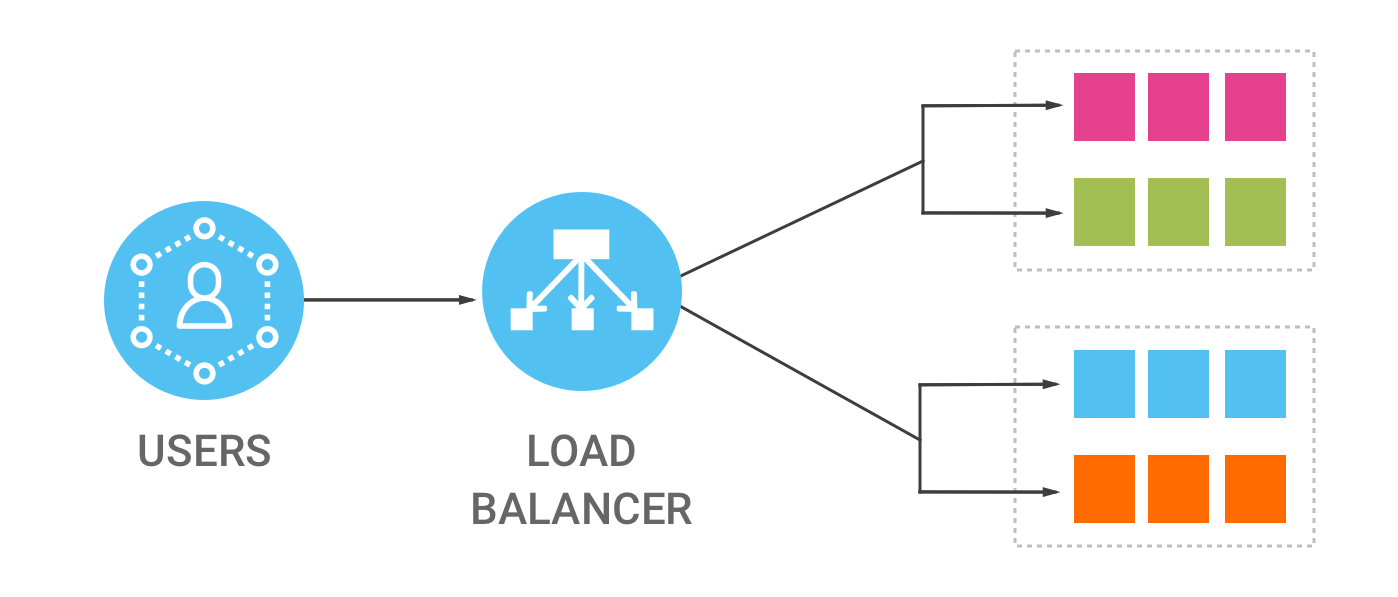
A load balancer is like a traffic cop for your delivery business. You know how when there's a lot of traffic, you need someone to direct it, so that everyone gets where they need to go on time? A load balancer is like that, but for the internet.
A load balancer is a device or a software that distributes the incoming traffic across multiple servers. It helps to ensure that the servers are not overloaded, and that the traffic is distributed evenly. It's like a traffic cop that helps to ensure that everyone gets where they need to go.
For example, if a website has many visitors, the load balancer will distribute the incoming traffic among multiple servers that host the website, this ensures that the website's performance is not affected by the high traffic and the visitors get the content fast.
So, in short, a load balancer is a device or a software that sits in front of multiple servers, and it directs incoming traffic to the appropriate server, it helps to ensure that the servers are not overloaded, and that the traffic is distributed evenly, it helps to improve the performance of the website, and the visitors get the content fast.
Server-Selection Strategy
Alright, so there are different ways that a load balancer can decide which server to send the traffic to, these are called server-selection strategies.
Round Robin is like spinning a wheel to decide. You know how when you play wheel of fortune, the wheel points to a person and that person has to do something? Round Robin is like that, but for servers. The load balancer sends the traffic to each server in a sequence, like spinning a wheel. Only thing is it normally goes in order.
Least Connections is like choosing the person with the least to do. You know how when you're choosing who to play with, you choose the person with the least to do? Least connections is like that, but for servers. The load balancer chooses the server with the least connections to handle the incoming traffic.
IP Hash is like choosing based on a person's address. You know how when you're sending a letter, you choose the post office based on the person's address? IP Hash is like that, but for servers. The load balancer chooses the server based on the client's IP address.
Weighted Round Robin is like choosing based on a person's preference. You know how when you're choosing who to play with, you choose based on a person's preference? Weighted Round Robin is like that, but for servers. The load balancer chooses the server based on a predefined weight assigned to each server.
So, in short, load balancers use different server-selection strategies to decide which server to send the traffic to, these strategies include: Round Robin, Least Connections, IP Hash, and Weighted Round Robin.
HotSpot
Alright, a HotSpot is like a bottleneck in your delivery business. You know how when you run a delivery business and one of your drivers gets stuck in traffic, it slows down all the other deliveries? A HotSpot is like that, but for servers.
A HotSpot is a situation where a single server in a load-balanced environment receives a disproportionate amount of traffic. This can happen when a load balancer's server-selection strategy is not working as intended or when a server is not able to handle the traffic it receives. It can cause the server to slow down, crash or even cause a failure in the service.
To avoid HotSpots, load balancers can use different server-selection strategies, or they can use health checks to monitor the servers and redirect the traffic to a different server if one server is not able to handle the traffic. Regular monitoring and maintenance of the servers can also help to prevent HotSpots.
So, in short, a HotSpot is like a bottleneck in your delivery business, it's a situation where a single server in a load-balanced environment receives a disproportionate amount of traffic, it can cause the server to slow down, crash or even cause a failure in the service, to avoid HotSpots, load balancers can use different server-selection strategies, or they can use health checks to monitor the servers and redirect the traffic to a different server if one server is not able to handle the traffic, regular monitoring and maintenance of the servers can also help to prevent HotSpots.
Hashing
Alright, so a Hashing Algorithm is like a secret recipe for your cookies. You know how when you make cookies, you have a secret recipe that you follow to make sure they turn out perfect every time? A Hashing Algorithm is like that, but for computers.
A Hashing Algorithm is a mathematical function that takes an input (or 'message') and returns a fixed-size string of characters, which is called the 'hash value'. The same input will always produce the same hash, but even a small change to the input will produce a very different hash. It's like a secret recipe that computers use to encrypt data and keep it secure.
For example, when you create a password, the computer uses a Hashing Algorithm to encrypt it, so even if someone gets access to the password, they wouldn't be able to know the actual password.
There are different types of Hashing Algorithms such as MD5, SHA-1, SHA-2 and SHA-3. Each one of them has its own way of encrypting the data and level of security.
So, in short, a Hashing Algorithm is like a secret recipe for your cookies, it's a mathematical function that takes an input (or 'message') and returns a fixed-size string of characters, the same input will always produce the same hash, but even a small change to the input will produce a very different hash, it's a way of encrypting data and keep it secure, there are different types of Hashing Algorithms such as MD5, SHA-1, SHA-2, and SHA-3, each one of them has its own way of encrypting the data and level of security.
Consistent Hashing
Alright, so consistent hashing is like using a master key for your deliveries. You know how when you run a delivery business, you have a master key that can open all the locks, so you don't have to keep switching keys for each delivery? Consistent Hashing is like that, but for servers.
Consistent Hashing is a method of distributing requests to servers in a distributed system, it's a way to distribute requests among servers in a way that is less sensitive to changes in the number of servers. It works by assigning each server a unique hash value, and then mapping the requests to the server with the closest hash value.
For example, if you have a system that needs to distribute requests among 10 servers, with consistent hashing, instead of re-mapping all requests to new servers when one server goes down or when new servers are added, only a fraction of the requests would need to be remapped.
So, in short, consistent Hashing is like using a master key for your deliveries, it's a method of distributing requests to servers in a distributed system, it's a way to distribute requests among servers in a way that is less sensitive to changes in the number of servers, it works by assigning each server a unique hash value, and then mapping the requests to the server with the closest hash value.
Rendevous Hashing
Alright, so Rendezvous Hashing is like using a master list for your deliveries. You know how when you run a delivery business, you have a master list of all the addresses, so you know exactly where to deliver the packages? Rendezvous Hashing is like that, but for servers.
Rendezvous Hashing is a method of distributing requests to servers in a distributed system, it works by assigning a weight to each server, based on its capacity, and then mapping the requests to the server with the highest weight for that specific request. It's similar to consistent hashing, but it uses a more sophisticated algorithm that takes into account the weight of each server, making it more suited for systems where servers have different capacity.
For example, if you have a system that needs to distribute requests among 10 servers, some with more capacity than others, with Rendezvous Hashing, you can assign more weight to servers with more capacity, and requests will be distributed accordingly, ensuring that servers with less capacity are not overloaded while the servers with more capacity will have less load.
So, in short, Rendezvous Hashing is like using a master list for your deliveries, it's a method of distributing requests to servers in a distributed system, it works by assigning a weight to each server, based on its capacity, and then mapping the requests to the server with the highest weight for that specific request, it's more suited for systems where servers have different capacity, by assigning more weight to servers with more capacity, it ensures that servers with less capacity are not overloaded while the servers with more capacity will have less load.
Secure Hash Algorithms (SHA)
Alright, so Secure Hashing Algorithm (SHA) is like using a secret recipe for your cookies, but the recipe is super secure. You know how when you make cookies, you have a secret recipe that you follow to make sure they turn out perfect every time? A Secure Hashing Algorithm is like that, but for computers and it's super secure.
SHA is a type of Hashing Algorithm that is used to encrypt data and keep it secure. It's like a secret recipe that computers use to encrypt data and it's considered to be more secure than other types of Hashing Algorithms. It's widely used in various applications like password storage, digital signature, and file integrity validation.
For example, when you create a password, the computer uses a Secure Hashing Algorithm to encrypt it, so even if someone gets access to the password, they wouldn't be able to know the actual password. It is also used for digital signature, to ensure that the message is not tampered with during the transmission and for file integrity validation, to check if the file is corrupted or not.
So, in short, Secure Hashing Algorithm (SHA) is like using a secret recipe for your cookies but the recipe is super secure, it's a type of Hashing Algorithm that is used to encrypt data and keep it secure, it's considered to be more secure than other types of Hashing Algorithms, it's widely used in various applications like password storage, digital signature, and file integrity validation.
Relational Databases
VS
Non Relational Databases
Alright, so a Relational Database is like a family tree. You know how when you have a family tree, it shows you how everyone is related to each other? A Relational Database is like that, but for data.
A Relational Database is a type of database that organizes data into tables, with rows and columns, similar to a spreadsheet. Each table has a unique key, called the primary key, that is used to link it to other tables. It's like a family tree that shows how data is related to each other.
On the other hand, a Non-Relational Database is like a big box of memories. You know how when you have a big box of memories, it's full of different things that don't have a specific order? A Non-Relational Database is like that, but for data.
A Non-Relational Database is a type of database that stores data in a format that is not organized into tables with rows and columns. It's more flexible and allows for data to be stored in a variety of formats, such as JSON or BSON. It's like a big box of memories that can store different types of data in no specific order.
So, in short, a Relational Database is like a family tree, it organizes data into tables, with rows and columns, each table has a unique key, called the primary key, that is used to link it to other tables, a Non-Relational Database is like a big box of memories, it stores data in a format that is not organized into tables with rows and columns, it's more flexible and allows for data to be stored in a variety of formats, such as JSON or BSON, it can store different types of data in no specific order.
Key-Value Stores
Alright, so a Key-Value Store is like a key-lock storage unit. You know how when you rent a storage unit, you get a key and you use it to open the unit and store your stuff? A Key-Value Store is like that, but for data.
A Key-Value Store is a type of NoSQL database that stores data in the form of key-value pairs, similar to a dictionary or javascript object. Each piece of data is stored with a unique key that is used to retrieve it. It's like a key-lock storage unit, where the key is used to store and retrieve the data.
For example, when you store a value "John Doe" with key "name", you can retrieve the value "John Doe" by using the key "name".
Key-Value Stores are highly scalable and can handle large amounts of data quickly and efficiently. They're often used in cases where the data structure is simple, and the primary concern is quick lookups and data retrieval.
So, in short, a Key-Value Store is like a key-lock storage unit, it's a type of NoSQL database that stores data in the form of key-value pairs, similar to a dictionary, each piece of data is stored with a unique key that is used to retrieve it, it's highly scalable and can handle large amounts of data quickly and efficiently, it's often used in cases where the data structure is simple, and the primary concern is quick lookups and data retrieval.
Replication and Sharding (Note MongoDB does this under the hood)

Alright, so Replication is like making copies of your delivery routes. You know how when you run a delivery business, you make copies of your routes so that if one copy gets lost, you still have another one? Replication is like that, but for data.
Replication is the process of creating multiple copies of the same data and distributing them across multiple servers. This way, if one server fails, another copy of the data is still available. It helps to improve the availability and reliability of the system.
On the other hand, Sharding is like breaking down your deliveries into smaller packages. You know how when you have a big delivery that won't fit in one truck, you break it down into smaller packages? Sharding is like that, but for data.
Sharding is the process of breaking down a large amount of data into smaller chunks and distributing them across multiple servers. It helps to improve the performance and scalability of the system by distributing the load across multiple servers.
So, in short, Replication is like making copies of your delivery routes, it's the process of creating multiple copies of the same data and distributing them across multiple servers, it helps to improve the availability and reliability of the system. Sharding is like breaking down your deliveries into smaller packages, it's the process of breaking down a large amount of data into smaller chunks and distributing them across multiple servers, it helps to improve the performance and scalability of the system by distributing the load across multiple servers.
Leader Election
Alright, so Leader Election is like choosing a leader for your group project. You know how when you're working on a group project, you have to choose a leader to make sure everyone is on the same page? Leader Election is like that, but for servers.
Leader Election is the process of selecting a single server to be the leader among a group of servers. This leader server is responsible for coordinating and managing the other servers in the group. It's like choosing a leader for your group project to make sure everyone is on the same page.
For example, in a distributed system, a leader server may be responsible for coordinating tasks such as data replication and handling client requests. In case the leader server fails, the other servers in the group will elect a new leader to take its place.
There are different algorithms that can be used to elect a leader, such as the Bully Algorithm or the Paxos Algorithm.
So, in short, Leader Election is like choosing a leader for your group project, it's the process of selecting a single server to be the leader among a group of servers, this leader server is responsible for coordinating and managing the other servers in the group. There are different algorithms that can be used to elect a leader, such as the Bully Algorithm or the Paxos Algorithm.
Peer to Peer Networks
Alright, so a Peer-to-Peer (P2P) network is like a group of friends sharing music files. You know how when you and your friends share music files with each other, you all have access to the same songs? A Peer-to-Peer network is like that, but for computers.
A Peer-to-Peer network is a type of network where each computer, or node, has the same capabilities and responsibilities. There is no central server controlling the network, and all nodes can act as both clients and servers. It's like a group of friends sharing music files with each other, where each friend has the ability to share and access files.
For example, in a P2P file-sharing network, each node can share and download files from other nodes, instead of relying on a central server. In a P2P network, each node is responsible for maintaining the data and security of its own network.
So, in short, a Peer-to-Peer (P2P) network is like a group of friends sharing music files, it's a type of network where each computer, or node, has the same capabilities and responsibilities, there is no central server controlling the network, and all nodes can act as both clients and servers, for example, in a P2P file-sharing network, each node can share and download files from other nodes, instead of relying on a central server, in a P2P network, each node is responsible for maintaining the data and security of its own network.
Rate Limiting
Alright, so Rate Limiting is like setting a speed limit on the highway. You know how when you're driving on the highway, there's a speed limit to make sure everyone is driving safely? Rate Limiting is like that, but for requests.
Rate Limiting is the process of controlling the rate at which a service is accessed, it's a way to prevent one user or service from overloading the system by making too many requests. It's like setting a speed limit on the highway to make sure everyone is driving safely.
For example, in a web application, rate limiting can be used to prevent a single user from making too many requests to the server in a short period of time, which can cause the server to crash. It can also be used to prevent a malicious user from launching a Distributed Denial of Service (DDOS) attack by overwhelming the server with too many requests.
There are various ways to implement rate limiting, such as token bucket, leaky bucket and fixed window algorithms.
So, in short, Rate Limiting is like setting a speed limit on the highway, it's the process of controlling the rate at which a service is accessed, it's a way to prevent one user or service from overloading the system by making too many requests. For example, in a web application, rate limiting can be used to prevent a single user from making too many requests to the server in a short period of time, which can cause the server to crash, it can also be used to prevent a malicious user from launching a Distributed Denial of Service (DDOS) attack by overwhelming the server with too many requests, there are various ways to implement rate limiting, such as token bucket, leaky bucket and fixed window algorithms.
Alright, so there are different ways to set speed limits on the highway, just like there are different ways to implement rate limiting.
The Token Bucket algorithm is like giving each driver a certain number of tokens, like a certain number of speeding tickets. Each time a driver exceeds the speed limit, they lose a token. If they don't have any more tokens, they get pulled over by the police. Similarly, in this algorithm, requests are allowed as long as there are tokens available in the bucket, and when the bucket is empty, the requests are blocked.
The Leaky Bucket algorithm is like the police catching speeders and putting them in a bucket. The bucket has a certain capacity and the police can only catch a certain number of speeders at a time. Similarly, in this algorithm, requests are added to a queue, and a certain number of requests are processed at a time.
The Fixed Window algorithm is like the police monitoring the speed limit for a certain period of time, like a hour. They keep track of the number of speeders caught during that time and if it exceeds a certain threshold, they take action. Similarly, in this algorithm, requests are tracked over a fixed period of time, and if they exceed a certain threshold, they are blocked.
So, in short, there are different ways to set speed limits on the highway, just like there are different ways to implement rate limiting, Token Bucket algorithm is like giving each driver a certain number of tokens, like a certain number of speeding tickets, each time a driver exceeds the speed limit, they lose a token, if they don't have any more tokens, they get pulled over by the police. Leaky Bucket algorithm is like the police catching speeders and putting them in a bucket, the bucket has a certain capacity and the police
Logging and Monitoring
Alright, so logging and monitoring is like keeping a diary and checking in on your progress. You know how when you're working on a project, you keep a diary to keep track of your progress and check in on it from time to time? Logging and monitoring is like that, but for computer systems.
Logging is the process of recording information about a system's activity, such as events, errors, and performance data. It's like keeping a diary of what you did, when you did it, and how it went. This information can be later used for troubleshooting, auditing and performance analysis.
Monitoring, on the other hand, is the process of continuously checking the status of a system and its components. It's like checking in on your progress to see how you're doing and if everything is working as expected. This information can be used to detect issues early and take corrective actions.
For example, in a web application, logging can be used to record information about requests, errors and performance, while monitoring can be used to check the usage of resources such as CPU, memory, and network.
So, in short, logging and monitoring is like keeping a diary and checking in on your progress, logging is the process of recording information about a system's activity, such as events, errors, and performance data, it's like keeping a diary of what you did, when you did it, and how it went, this information can be later used for troubleshooting, auditing and performance analysis. Monitoring, on the other hand, is the process of continuously checking the status of a system and its components, it's like checking in on your progress to see how you're doing and if everything is working as expected, this information can be used to detect issues early and take corrective actions.
Publish/Subscribe Pattern
Alright, so the Publish/Subscribe pattern is like a newspaper delivery service. You know how when you subscribe to a newspaper, the newspaper company delivers the newspaper to you every day? The Publish/Subscribe pattern is like that, but for computer systems.
In this pattern, there are three main components: publishers, subscribers, and a message broker. The publishers are like the newspaper company, they send out messages, or "publish" them. The subscribers are like the people who subscribe to the newspaper, they receive the messages or "subscribe" to them. The message broker is like the delivery service, it receives messages from the publishers and delivers them to the subscribers who have expressed an interest in receiving them.
This pattern allows for loose coupling between the publishers and subscribers, meaning that the publishers don't need to know who is subscribed to their messages and the subscribers don't need to know who is publishing them. This allows for a more flexible and scalable system.
For example, in a social media application, a user can "subscribe" to other users' updates and receive their posts, without the need for the users to be directly connected.
So, in short, The Publish/Subscribe pattern is like a newspaper delivery service, it allows for loose coupling between the publishers and subscribers, meaning that the publishers don't need to know who is subscribed to their messages and the subscribers don't need to know who is publishing them, this allows for a more flexible and scalable system. There are three main components: publishers, subscribers, and a message broker, the publishers are like the newspaper company, they send out messages, the subscribers are like the people who subscribe to the newspaper, they receive the messages and the message broker is like the delivery service, it receives messages from the publishers and delivers them to the subscribers who have expressed an interest in receiving them.
MapReduce
Alright, so MapReduce is like cooking a big meal for a party. You know how when you're cooking a big meal for a party, you have to do certain tasks like chopping vegetables and then cooking them, then combining them all together? MapReduce is like that, but for big data processing.
MapReduce is a programming model that allows for the processing of large amounts of data in parallel across a cluster of machines. It consists of two main phases: the map phase and the reduce phase. The map phase is like chopping vegetables, it takes the input data and processes it into a intermediate form. The reduce phase is like cooking and combining the vegetables, it takes the intermediate data and combines it to produce the final output.
The MapReduce programming model allows for the processing of large data sets in parallel by breaking down the data into smaller chunks and processing them on different machines. This allows for a more efficient use of resources and faster processing times.
For example, in a search engine, MapReduce can be used to process large amounts of data, such as web pages and their contents, to generate indexes for faster search results.
So, in short, MapReduce is like cooking a big meal for a party, it's a programming model that allows for the processing of large amounts of data in parallel across a cluster of machines, it consists of two main phases: the map phase and the reduce phase, the map phase is like chopping vegetables, it takes the input data and processes it into a intermediate form. The reduce phase is like cooking and combining the vegetables, it takes the intermediate data and combines it to produce the final output, it allows for the processing of large data sets in parallel by breaking down the data into smaller chunks and processing them on different machines, this allows for a more efficient use of resources and faster processing times.
Design Systems
Alright, so the "Gang of Four" is a group of four computer scientists who wrote a book about design patterns in software development. They listed 23 design patterns that are widely used in software development. However, as it would take a lot of time to explain all of them, I will just list them out and give an overview of what they are and their purpose:
Creational Patterns: These patterns are used to create objects and classes. They include:
- Abstract Factory: Provides an interface for creating families of related or dependent objects without specifying their concrete classes.
- Builder: Separates the construction of a complex object from its representation, allowing the same construction process to create various representations.
- Factory Method: Defines an interface for creating an object, but lets subclasses decide which class to instantiate.
- Prototype: Specifies the kind of objects to create using a prototypical instance, and creates new objects by copying this prototype.
-
Singleton: Ensures a class has only one instance and provides a global access point to this instance.
Structural Patterns: These patterns are used to compose objects and classes into larger structures. They include:
- Adapter: Allows classes with incompatible interfaces to work together by wrapping its own interface around that of an already existing class.
- Bridge: Decouples an abstraction from its implementation, allowing the two to vary independently.
- Composite: Compose objects into tree structures to represent part-whole hierarchies.
- Decorator: Attaches additional responsibilities to an object dynamically, providing a flexible alternative to subclassing for extending functionality.
- Facade: Provides a unified interface to a set of interfaces in a subsystem, hiding their complexities from the client.
- Flyweight: A fine-grained instance used for efficient sharing of information that is contained elsewhere.
-
Proxy: Provides a surrogate or placeholder for another object to control access to it.
Behavioral Patterns: These patterns are used to manage communication and the flow of control between objects and classes. They include:
- Chain of Responsibility: Allows multiple objects to handle a request without specifying the receiver explicitly.
- Command: Encapsulate a request as an object, thereby letting you parametrize clients with different requests, queue or log requests, and support undoable operations.
- Interpreter: Defines a language and provides an interpreter for that language.
- Iterator: Provides a way to access the elements of an aggregate object sequentially without exposing its underlying implementation. It's like a playlist on your phone. When you're listening to music, you can go through the songs in the order that they are in the playlist without having to know how the playlist is organized or implemented. It allows you to access the individual elements of a collection of objects in a consistent and organized way without having to know how the collection is implemented. This allows for a more flexible and maintainable code as the implementation of the collection can change without affecting the code that uses it
- Mediator: Allows objects to communicate without knowing each other's identities.
- Memento: Captures an object's internal state to be able to restore it later.
- Observer: Allows objects to be notified of changes to other objects without the notified objects having to know the identities of the notifiers.
- State: Allows an object to change its behavior when its internal state changes.
- Strategy: Allows an object to change its behavior at runtime by switching to a different strategy.
- Template Method: Defines the skeleton of an algorithm in a method, allowing subclasses to fill in the details.
- Visitor: Separates an algorithm from the object structure on which it operates.
These design patterns are commonly used in software development to solve common problems and improve code organization, maintainability, and readability. They are not specific to any programming language or framework, and can be applied to different contexts and domains. Each pattern provides a solution to a problem and a way to implement it in a specific context.
JavaScript Questions You Should Be Able To Answer
JavaScript Data Types
So JavaScript has several different data types, and they are like different types of food. You know how food can be classified as a fruit, vegetable, meat, or something else? JavaScript data types can be classified as string, number, boolean, object, and a few others.
- A string is like a sentence or a word, it's a set of characters. For example, a person's name, a sentence, or a word.
- A number is a numerical value. It can be an integer like 42 or a decimal like 3.14.
- A boolean is a true or false value. It's a value that can be either true or false, it's used in conditional statements and logical operations.
- An object is like a collection of properties, it's a set of key-value pairs that can store any type of data. It can be used to represent anything from a single value to a complex data structure.
- There is also null & undefined which represent the absence of value. A variable starts as undefined until its given a value and null is something that has been intentionally set to nothing.
So, in short, JavaScript has several different data types, like different types of food, a string is like a sentence or a word, it's a set of characters, a number is like a numerical value, it can be an integer or a decimal, a boolean is like a true or false statement, it's a value that can be either true or false, it's used in conditional statements and logical operations, an object is like a collection of properties, it's a set of key-value pairs that can store any type of data.
Difference Between Const Let and Var
Alright, so in JavaScript, there are three ways to declare a variable: using const, let, and var. These are like three different types of containers you can use to store things.
const is like a mason jar, it's a container that you can put something in and it will always stay the same. Once you put something in a const container, you can't change it. For example, if you declare a variable as const age = 25, you can't change the value of age to 30 later on. It's a way to ensure that a variable's value will not be changed by mistake.
let is like a Tupperware container, it's a container that you can put something in and you can change it later if you need to. For example, if you declare a variable as let age = 25, you can change the value of age to 30 later on. It's a way to declare variables whose values will change over time.
var is like an old-fashioned container, it's a container that you can put something in and it's accessible everywhere in the code. It's similar to let but with a different scope behavior. The difference is that var variables are function-scoped, while let and const are block-scoped.
So, in short, in JavaScript, there are three ways to declare a variable: using const, let, and var, these are like three different types of containers you can use to store things, const is like a mason jar, it's a container that you can put something in and it will always stay the same, let is like a Tupperware container, it's a container that you can put something in and you can change it later if you need to and var is like an old-fashioned container, it's a container that you can put something in and it's accessible everywhere in the code.
Pass By Value vs Pass By Reference
Alright, so in JavaScript, when you pass a value to a function or assign a value to a variable, it can be passed either by value or by reference. It's like passing a note or a book to a friend.
When you pass by value, it's like giving your friend a photocopy of the note. The note you have and the copy your friend has are separate and independent of each other. Any changes made to the copy won't affect the original note.
When you pass by reference, it's like giving your friend the original note. The note you have and the note your friend has are the same thing, they are connected. Any changes made to the note by your friend will affect the original note as well.
In JavaScript, primitive data types like numbers, strings, and booleans are passed by value. This means when you pass a primitive data type to a function or assign it to a variable, a copy of the value is made. Any changes made to the copy will not affect the original value.
Objects and arrays, on the other hand, are passed by reference. This means when you pass an object or array to a function or assign it to a variable, a reference to the original value is used. Any changes made to the object or array will affect the original value.
So, in short, in JavaScript, when you pass a value to a function or assign a value to a variable, it can be passed either by value or by reference, it's like passing a note or a book to a friend, when you pass by value, it's like giving your friend a photocopy of the note, the note you have and the copy your friend has are separate and independent of each other, any changes made to the copy won't affect the original note, when you pass by reference, it's like giving your friend the original note, the note you have and the note your friend has are the same thing, they are connected, any changes made to the note by your friend will affect the original note as well, Primitive data types like numbers, strings, and booleans are passed by value, objects and arrays, on the other hand, are passed by reference.
Map , Filter and Reduce ( Mutation or not)
Sure, so in JavaScript, we have a alot of built-in methods that can help us work with arrays, 3 reign supreme and these are map, filter, and reduce. These methods are like different kitchen tools you can use to cook up your arrays.
map is like a frying pan, you use it to cook up a new version of your array with new values. It allows you to iterate over an array, perform a certain operation on each element, and return a new array with the result of those operations. For example, you can use map to double every element in an array of numbers.
filter is like a sieve, you use it to filter out the elements you don't need from your array. It allows you to iterate over an array and return a new array with only the elements that pass a certain test. For example, you can use filter to only keep even numbers in an array of numbers.
reduce is like a mixing bowl, you use it to mix all the elements in your array together to create one final value. It allows you to iterate over an array, perform a certain operation on each element, and return a single value that is the result of those operations. For example, you can use reduce to sum all the numbers in an array of numbers.
So, in short, map is like a frying pan, it allows you to cook up a new version of your array with new values, filter is like a sieve, it allows you to filter out the elements you don't need from your array, reduce is like a mixing bowl, it allows you to mix all the elements in your array together to create one final value. These methods are useful for making changes to arrays, filtering out certain elements, or reducing arrays to a single value.
Falsey Values
Alright, so in JavaScript, there are certain values that are considered "truthy" and others that are considered "falsey". It's like a statement that can be true or false.
A truthy value is like a statement that is true, it's a value that will evaluate to true when used in a boolean context. For example, a non-empty string, a non-zero number, or an object are considered truthy values.
A falsey value is like a statement that is false, it's a value that will evaluate to false when used in a boolean context. For example, an empty string, the number 0, NaN , undefined or null are considered falsey values.
So, in short, truthy values are like statements that are true and falsey values are like statements that are false. Certain values in JavaScript are considered truthy and others are considered falsey, this plays an important role when using them in conditional statements or any other logical operation.
Closure
A closure in JavaScript is like a secret handshake. It's a way of keeping certain information private, and only allowing certain people who know the secret handshake to access it.
In JavaScript, a closure is a function that remembers the variables in the scope where it was created, even when that function is executed elsewhere. It's like a secret handshake, the function has access to the variables defined in the scope where it was created, even if it's executed in another place, and only the people who know the secret handshake, who have access to the closure, can use these variables.
Closures are useful for creating private variables and methods, and for creating stateful functions. It's like a secret handshake that allows you to keep certain information private and only certain people can access it.
So, in short, a closure in JavaScript is like a secret handshake, it's a way of keeping certain information private, and only allowing certain people who know the secret handshake to access it, the function has access to the variables defined in the scope where it was created, even if it's executed in another place, and only the people who know the secret handshake, who have access to the closure, can use these variables.
Scope
Scope in JavaScript is like the hood you grew up in, it's the area where certain variables, functions, and objects can be seen and used. It's all about what's visible where, and the context in which things are runnin'.
JavaScript got two types of hoods, the global hood and the local hood. If a variable is declared outside of any function or block, it's in the global hood and can be seen from anywhere. But if a variable is declared inside a function or block, it's in the local hood and can only be seen in that function or block.
JavaScript also got function hoods, where each function got its own hood and any variables or functions declared within it can only be seen within that function.
JavaScript also got block hoods, where any variables or functions declared within a block (e.g. if statement, for loop) can only be seen within that block and not outside of it.
JavaScript also uses something called hoisting, which is like moving things up in the hood, variable and function declarations are moved to the top of their hood during the compilation phase.
In summary, Scope in JavaScript is like the hood you grew up in, it's the area where certain variables, functions, and objects can be seen and used. JavaScript got two types of hoods, global and local, function hoods and block hoods and uses hoisting.
Promises
A JS Promise is like a promise you make to somebody. It's a way to handle the result of an asynchronous operation in JavaScript. You can think of it like a "promise" to do something and once it's done, it either keeps its promise and returns the result, or it breaks its promise and returns an error.
You can create a promise by using the new Promise() constructor. Inside of the constructor, you pass in a function that takes two arguments, resolve and reject.
The resolve function is called when the promise is fulfilled, and the reject function is called when the promise is rejected.
You can use the .then() method to attach a callback function that will be called when the promise is resolved. Similarly, you can use the .catch() method to attach a callback function that will be called when the promise is rejected.
Promises are useful in situations where you need to perform an asynchronous operation and do something with the result. For example, when you need to fetch data from a server, you can use a promise to handle the response once it comes back.
In summary, a JS Promise is a way of handling the results of an asynchronous operation, it's like a promise you make to somebody, it can be fulfilled or rejected and you can attach callbacks to it using the .then() and .catch() methods.
Speed Up a Slow App
Yo, so if a app is runnin' slow, there's a few things we can do to speed it up.
First things first, we need to figure out what's causin' the slow down. Is it the network? Is it the server? Is it the code? Once we pinpoint the problem, we can start fixin' it.
If it's the network, we might try usin' a Content Delivery Network, or CDN for short. A CDN is like a shortcut to the server, it stores a copy of the app's data closer to the user so it can be loaded faster.
If it's the server, we might try addin' more resources like memory or storage. Or we can look into optimizin' the server's configs and settings.
If it's the code, we can try optimizin' the app's performance by reducin' the amount of data that's bein' loaded and processed, or by usin' better algorithms. We can also try implementin' caching so that frequently used data can be loaded faster.
Another thing we can do is to use Profiling tools to identify which part of the app is slow and optimize it.
Lastly, we can try to minimize the number of requests made to the server by implementing client-side rendering, or by using pre-fetching and pre-loading techniques.
In summary, there are several ways to speed up a slow app, such as using a CDN, adding more resources to the server, optimizing the code, Profiling, minimizing the number of requests and using techniques like client-side rendering, pre-fetching, and pre-loading.
Client-side rendering is when the app's data is rendered on the user's device, instead of on the server. This can speed up the app's performance because the data doesn't have to travel over the network to be rendered. It can also reduce the load on the server.
Pre-fetching is when the app starts loading data before the user even needs it. This can make the app feel faster because the data is already loaded and ready to go when the user needs it. This can also reduce the load on the server because the data is loaded in advance.
Pre-loading is similar to pre-fetching, but it's more focused on specific parts of the app. Instead of loading all the data, pre-loading only loads the data that's likely to be needed next. This can help to speed up the app by reducing the amount of data that needs to be loaded on demand.
In summary, client-side rendering, pre-fetching and pre-loading are techniques that can help to speed up a slow app by reducing the amount of data that needs to be loaded, reducing the load on the server and making the app feel faster to the user by loading the data in advance.
CRUD
CRUD is like the ABCs of application development, like Jay-Z's ABCs of making hit songs. It's a set of basic operations that are used to manage data in most applications.
- C(reate): This is like Jay-Z writing a new verse. Creating new data, it's like writing a new verse for a song, you're adding new information to the database.
- R(ead): This is like Jay-Z reading the lyrics. Retrieving data from the database, it's like reading the lyrics of a song, you're getting information from the database.
- U(pdate): This is like Jay-Z editing a verse. Updating data, it's like editing a verse of a song, you're changing existing information in the database.
- D(elete): This is like Jay-Z deleting a verse. Deleting data, it's like deleting a verse from a song, you're removing information from the database.
So, in short, CRUD is like the ABCs of application development, like Jay-Z's ABCs of making hit songs, it's a set of basic operations that are used to manage data in most applications, C(reate): Creating new data, R(ead): Retrieving data from the database, U(pdate): Updating data, D(elete): Deleting data.
CRAP
CRAP is like the do's and don'ts of fashion design, like a fashion designer's rule book. It's a set of principles that can help you create web design that is easy to use and easy to look at.
- Contrast: This is like a fashion designer using contrasting colors. Having elements that stand out and are easily distinguishable, it's like a fashion designer using contrasting colors to make an outfit pop.
- Repetition: This is like a fashion designer repeating patterns. Having elements that are repeated throughout the design, it's like a fashion designer repeating patterns to create a cohesive look.
- Alignment: This is like a fashion designer making sure everything is in the right place. Having elements that are lined up and balanced, it's like a fashion designer making sure everything is in the right place to create a polished look.
- Proximity: This is like a fashion designer grouping similar items together. Having elements that are grouped together and separated from others, it's like a fashion designer grouping similar items together to create a clean look.
So, in short, CRAP is like the do's and don'ts of fashion design, like a fashion designer's rule book, it's a set of principles that can help you create web design that is easy to use and easy to look at, Contrast: Having elements that stand out and are easily distinguishable, Repetition: Having elements that are repeated throughout the design, Alignment: Having elements that are lined up and balanced, Proximity: Having elements that are grouped together and separated from others.
SOLID
SOLID is like a blueprint for building good code, like Jay-Z's blueprint for making hit songs. It's a set of principles that, when followed, can help you write code that is easy to understand, easy to change, and easy to test.
- Single Responsibility Principle: This is like a Jay-Z song having a clear theme or message. Each class should have only one reason to change, it's like a song that has a clear theme or message, it's easy to understand and easy to remember.
- Open-Closed Principle: This is like Jay-Z being open to new ideas but staying true to his style. A class should be open for extension but closed for modification, it's like Jay-Z being open to new ideas but staying true to his style, you can add new features without changing the existing code.
- Liskov Substitution Principle: This is like Jay-Z not using a different rapper's flow. derived classes should be substitutable for their base classes, it's like Jay-Z not using a different rapper's flow, if you have a class "A" and a derived class "B", you should be able to use "B" wherever you use "A" and it should work the same way.
- Interface Segregation Principle: This is like Jay-Z collaborating with different artists. Classes should not be forced to implement interfaces they do not use, it's like Jay-Z collaborating with different artists, if you have a class that doesn't need certain methods, you shouldn't force it to implement them.
- Dependency Inversion Principle: This is like Jay-Z not depending on just one record label. High-level modules should not depend on low-level modules, it's like Jay-Z not depending on just one record label, you should be able to change the lower-level modules without affecting the higher-level ones.
So, in short, SOLID is like a blueprint for building good code, like Jay-Z's blueprint for making hit songs, it's a set of principles that, when followed, can help you write code that is easy to understand, easy to change, and easy to test, Single Responsibility Principle: Each class should have only one reason to change, Open-Closed Principle: A class should be open for extension but closed for modification, Liskov Substitution Principle: derived classes should be substitutable for their base classes, Interface Segregation Principle: Classes should not be forced to implement interfaces they do not use, Dependency Inversion Principle: High-level modules should not depend on low-level modules.
OOP
OOP stands for Object-Oriented Programming, it's a way of writing code that organizes it into reusable chunks called objects. It's like building with LEGOs. Each LEGO brick is an object, and you can use it to build different things by combining it with other bricks. In the same way, objects in OOP are reusable chunks of code that you can use to build different parts of your program.
In OOP, objects are created from a blueprint called a class. A class is like a mold, it defines the properties and methods that the objects created from it will have. It's like a mold to make a lego brick, you can use it to create many lego bricks with the same shape and size.
Objects created from a class are called instances, and they can have their own unique properties and methods. It's like making multiple lego bricks using the same mold, each brick will have the same shape and size but different colors or patterns.
OOP also has the concept of inheritance, it's like a child inheriting traits from its parents. A class can inherit properties and methods from another class, it's like a child lego brick inheriting the shape and size from its parent brick.
So, in short, OOP stands for Object-Oriented Programming, it's a way of writing code that organizes it into reusable chunks called objects, it's like building with LEGOs, each LEGO brick is an object, and you can use it to build different things by combining it with other bricks, in OOP, objects are created from a blueprint called a class, and objects created from a class are called instances, OOP also has the concept of inheritance, it's like a child inheriting traits from its parents.
Sure, OOP can be explained using an acting analogy. So, in an acting performance, you got different characters, each one with its own unique personality, behavior, and attributes, same way in OOP, you got different objects, each one with its own properties and methods.
A class is like a script, it's a blueprint that defines the role and behavior of a character. It's like the director telling you what lines to say and how to act, the class defines what properties and methods an object should have.
An object is like an actor, it's a specific instance of a character that brings the script to life. It's like an actor taking on a role, the object is an instance of the class, it has all the properties and methods defined in the class.
Inheritance is like an understudy, it's when one character takes on the role of another character. It's like an understudy learning a role, inheritance allows one class to inherit properties and methods from another class.
So, in short, OOP can be explained using an acting analogy, objects are like characters, each one with its own unique personality, behavior, and attributes, a class is like a script, it's a blueprint that defines the role and behavior of a character, an object is like an actor, it's a specific instance of a character that brings the script to life, Inheritance is like an understudy, it's when one character takes on the role of another character, it allows one class to inherit properties and methods from another class.
Functional Programming
Sure, Functional Programming (FP) is a way of writing code that is based on the idea of treating functions as first-class citizens. It's like a recipe book. Each recipe is a function and you can use it to make different dishes by combining it with other ingredients. In the same way, functions in FP are reusable chunks of code that you can use to build different parts of your program.
In FP, the main idea is to avoid changing the state of the program, it's like a chef that only uses fresh ingredients and doesn't cook them. This means that you should not use variables that change their value over time and you should avoid using side effects that change the state of the program.
FP also focuses on immutability, it's like a chef that makes a dish and serves it. Once a value is created, it should not be changed, it's like a chef that makes a dish and once it's done, it's served and cannot be changed.
FP also encourages the use of pure functions, it's like a chef that follows a recipe exactly. A pure function is a function that, given the same input, will always return the same output, without any side effects.
So, in short, Functional Programming (FP) is a way of writing code that is based on the idea of treating functions as first-class citizens, it's like a recipe book, each recipe is a function and you can use it to make different dishes by combining it with other ingredients, in FP, the main idea is to avoid changing the state of the program, it also focuses on immutability, which means that values should not be changed once they are created and it also encourages the use of pure functions, which are functions that, given the same input, will always return the same output, without any side effects.
Recursion
Recursion is like a game of telephone. You have a message that you want to pass on to someone, but instead of telling them directly, you tell it to someone else, and they tell it to someone else, and so on. The message keeps getting passed on until it reaches the person you want it to reach. In the same way, recursion is when a function calls itself, until it reaches a certain condition.
A recursive function is like a game of telephone where the message is the function itself, and the people passing it on are the function calls. A recursive function calls itself, passing a modified version of the original inputs until it reaches a base case.
The base case is like the person you want to reach, it's the point at which the function stops calling itself and returns a final value. It's like the final person in the game of telephone that receives the message, the base case is the stopping point of the recursion, when it's reached the function stops calling itself and returns the final value.
So in short, recursion is like a game of telephone, where a message is passed on through different people, in the case of a function it's calling itself, passing a modified version of the original inputs until it reaches a base case, which is the stopping point of the recursion, when it's reached the function stops calling itself and returns the final value.
Putting this into practice....
Build Twitter
Designing a system like Twitter from scratch is like building a house from the ground up. You gotta have a plan, and you gotta make sure it's solid.
First, we gotta make sure that the house stays standing, even if a storm comes through. We gotta have 5 nines of availability, which means that the house (or the website) has to be up and running 99.999% of the time. That's like building a house on stilts, so that it can handle a flood or a hurricane.
Next, we gotta make sure the house can fit all the people who wanna come through. We gotta be able to handle 100 million users, that's like building a house with a lot of rooms, so that everyone can have a place to stay.
To do this, we're gonna need a big front door, that's like a load balancer. The load balancer is gonna make sure that everyone who comes through the front door is directed to the right place.
Once inside, we're gonna need a lot of rooms, that's like having a lot of servers. The servers are gonna handle all the different requests and make sure that everyone has a place to stay.
We're also gonna need a way to keep track of everyone's stuff, that's like having a database. The database is gonna store all the tweets and the user information, so that we can keep track of everything.
Finally, we're gonna need a way to keep the place clean, that's like having monitoring and logging. We're gonna need to keep an eye on everything that's going on in the house, so that we can make sure that everything is running smoothly and fix any problems that come up.
So, in short, designing a system like Twitter from scratch is like building a house from the ground up, you gotta have a plan, and you gotta make sure it's solid. We gotta make sure the house stays standing, even if a storm comes through, by having 5 nines of availability, We gotta make sure the house can fit all the people who wanna come through by being able to handle 100 million users, by having a big front door, that's like a load balancer, a lot of rooms, that's like having a lot of servers, a way to keep track of everyone's stuff, that's like having a database, and a way to keep the place clean, that's like having monitoring and logging.
To build a system like Twitter from scratch, we would use a variety of different technologies.
- Load Balancer: We would use a load balancer like HAProxy or Nginx to handle the high traffic and distribute the load among multiple servers. This would ensure that the site stays up and running even if one server goes down.
- Servers: We would use a cluster of servers, running something like Linux or Unix, that would handle the processing of user requests and store the tweets. We can use technologies like Kubernetes or Docker to manage our servers and make sure they are running smoothly.
- Database: We would use a database like MySQL or Cassandra to store the tweets and user information. We would use a technique like sharding to distribute the data across multiple servers, so that the database can handle the high volume of requests.
- Monitoring and Logging: We would use tools like Prometheus, Grafana, and ELK Stack to monitor the performance of the servers and the database, and to keep track of any errors or issues that arise.
- Cloud Infrastructure: We would use cloud infrastructure providers like Amazon Web Services, Google Cloud Platform, or Microsoft Azure to host our servers, databases, and load balancers, as well as to provide additional services like storage and data backup.
- Content Delivery Network: To ensure fast loading times for users all around the world, we would use a Content Delivery Network (CDN) like Akamai, Cloudflare, or Amazon Cloudfront.
- Security: We would implement security measures like encryption, firewalls, and access control to protect the site and user data from potential threats.
So in short, to build a system like Twitter from scratch, we would use technologies like Load balancer, Servers, Database, Monitoring and Logging, Cloud Infrastructure, Content Delivery Network and Security measures to ensure the site is fast, secure and can handle the high volume of requests and data.
Keeping that in mind you can use that framework to explain how to build anything
Myspace
To build a system like MySpace from scratch, the basic architecture would be similar to that of building a system like Twitter, we would use a variety of different technologies such as Load balancer, Servers, Database, Monitoring and Logging, Cloud Infrastructure, Content Delivery Network and Security measures to ensure the site is fast, secure and can handle the high volume of requests and data.
However, there would be some key differences in the way we would build MySpace vs Twitter.
- MySpace was heavily focused on personalization and customization of profile pages, which would require more complex front-end design and development. This would require a different approach in terms of front-end technologies and tools to support user-generated content and personalization features.
- MySpace also had a more complex social networking feature, which would require more advanced back-end logic and data modeling to support features like friend connections, messaging and groups.
- MySpace also had a music feature which would require additional storage and bandwidth to handle large audio files and streaming capabilities.
- In terms of scalability, MySpace's user base grew rapidly in a short period of time, so it would require more advanced techniques to handle the sudden increase in traffic and data, such as horizontal scaling and distributed systems.
In summary, while the basic architecture of building a system like MySpace and Twitter would be similar, the key differences would lie in the front-end design and development, back-end logic and data modeling, music feature, and scalability. To build a system like MySpace, it would require more advanced technologies and techniques to handle the complex features and sudden increase in traffic and data.
Facebook Messenger
If we were designing Facebook Messenger, there would be several key differences compared to building a system like Twitter or MySpace. These include:
- Real-time messaging: One of the key features of Facebook Messenger is the ability to send and receive messages in real-time, which would require a different set of technologies and design patterns to handle the high-frequency, low-latency traffic.
- Push notifications: Another important feature of Facebook Messenger is the ability to send push notifications to users when they receive new messages, which would require a different set of technologies and protocols to handle the real-time delivery of notifications.
- Chatbot integration: Facebook Messenger has a large ecosystem of chatbots and businesses, which would require more advanced back-end logic to handle the interactions between users and chatbots.
- Rich media: Facebook Messenger supports sending and receiving different types of media such as photos, videos, GIFs, and files, which would require more storage and bandwidth.
- Multi-Platform support: Facebook messenger is available on multiple platforms, including iOS, Android, Web, and Desktop, so it would require a more advanced approach in terms of cross-platform development and compatibility.
- Security: As Facebook messenger is handling private conversations, security would be a top priority, and we would implement end-to-end encryption, access control, and other security measures to protect user data.
In summary, while the basic architecture of building a system like Facebook messenger would be similar to building a system like Twitter or MySpace, the key differences would lie in the real-time messaging, push notifications, chatbot integration, rich media, multi-platform support, and security. To design Facebook messenger it would require advanced technologies and techniques to handle the real-time, high-frequency, low-latency traffic and the different type of media.
Designing a system like Instagram would have similarities as well as some differences compared to building a system like Twitter, MySpace or Facebook Messenger. These include:
- High-performance image and video handling: Instagram is primarily focused on visual content, so it would require a different set of technologies and design patterns to handle the high-performance storage, retrieval, and processing of images and videos. This would include things like image and video compression, thumbnail generation, and image processing techniques like image recognition, and machine learning.
- User-generated content: Instagram is built around user-generated content, which would require a more advanced approach to handling and moderating the large amount of data being uploaded. This would include things like content moderation, image recognition, and machine learning.
- Social networking: Similar to MySpace, Instagram also has social networking features such as following, commenting, and direct messaging.
- Mobile-first approach: Instagram is a mobile-first application and has a very large user base on mobile platforms, so it would require a more advanced approach in terms of mobile development and optimization, such as responsive design and offline support.
- Story feature: Instagram has a story feature, which is a temporary and more casual way of sharing content. This would require additional development work to handle the different type of content and the expiration of the story feature.
- Personalization: Instagram has a personalized feed which shows content tailored to the user's preference and history, this would require more advanced back-end logic and data modeling.
In summary, while the basic architecture of building a system like Instagram would be similar to building a system like Twitter, MySpace, or Facebook Messenger, the key differences would lie in the high-performance image and video handling, user-generated content, mobile-first approach, story feature, personalization and social networking. To design Instagram it would require advanced technologies and techniques to handle the high-performance image and video handling and personalization features, as well as a mobile-first approach.
Discord
Designing a system like Discord would have similarities as well as some differences compared to building a system like Twitter, MySpace, Facebook Messenger or Instagram. These include:
- Real-time voice and text messaging: Discord is a voice and text chat platform that's built for communities and gaming. It would require a different set of technologies and design patterns to handle the high-frequency, low-latency traffic for real-time voice and text messaging.
- Server-based architecture: Discord is built around the concept of servers, where users can join different servers and communicate with other users within that server. This would require a different approach in terms of data modeling and management, as well as access control and security.
- Push notifications: Discord has push notifications for when users receive new messages, and also has the feature of server-wide notifications.
- Rich media: Discord supports sending and receiving different types of media such as images, videos, GIFs, and files, which would require more storage and bandwidth.
- Multi-Platform support: Discord is available on multiple platforms, including iOS, Android, Web, and Desktop, so it would require a more advanced approach in terms of cross-platform development and compatibility.
- Gaming-specific features: Discord has a variety of features that are specific to gaming, such as the ability to join and create game-specific channels, and the ability to stream gameplay.
- Security: As Discord is handling private conversations, security would be a top priority, and we would implement end-to-end encryption, access control, and other security measures to protect user data.
In summary, while the basic architecture of building a system like Discord would be similar to building a system like Twitter, MySpace, Facebook Messenger or Instagram, the key differences would lie in the real-time voice and text messaging, server-based architecture, push notifications, rich media, multi-platform support, gaming-specific features and security. To design Discord it would require advanced technologies and techniques to handle the real-time, high-frequency, low-latency traffic, server-based architecture and gaming-specific features.