Lesson: Why Software Engineers Make So Much Money

By the End on this Lesson Students Will Be Able To:
- Understand the Value of Software Engineers: SWBAT explain why software engineers, particularly those skilled in modern technologies like React, are highly compensated due to their ability to create efficient, scalable, and dynamic user interfaces that save companies time and money.
- Grasp Big O Notation: SWBAT describe Big O Notation and its importance in evaluating the efficiency of algorithms in terms of time and space, which is crucial for writing scalable and efficient code.
- Differentiate Between Linear and Binary Search: SWBAT compare and contrast linear search and binary search algorithms, understanding their time complexities (O(n) and O(log n), respectively) and the scenarios in which each is most effective.
- Implement Basic React Concepts: SWBAT set up a React application using
create-react-appand understand the foundational concepts of React, including components, JSX, and props. - Manage State in React: SWBAT utilize React's
useStatehook to manage and update component state, enabling the creation of dynamic and interactive user interfaces. - Build a Counter Application: SWBAT follow a guided code-along to build a simple counter application in React, demonstrating the practical application of state management.
- Apply Conditional Rendering: SWBAT use React state to conditionally render UI elements, enhancing the application's interactivity and user experience.
- Create Reusable Components: SWBAT design and implement reusable React components, understanding how component reusability leads to more efficient development processes.
- Optimize UI Development with React: SWBAT articulate how React's component-based architecture and efficient state management contribute to faster development times, reduced costs, and improved user experiences.
- Reflect on the Impact of Efficient Algorithms: SWBAT discuss the broader implications of choosing the right algorithm for a task, including how such decisions can affect a company's operational efficiency and bottom line.
Introduction
Top software engineers, especially those working at big data companies, can command salaries exceeding $500,000 per year. This high compensation reflects not just their coding skills but their ability to solve complex problems efficiently, saving companies millions of dollars. A key concept that enables such efficiency is Big O Notation, a fundamental principle in computer science that evaluates the performance of algorithms.
Understanding Big O Notation
Big O Notation is the mathematical language that reveals the efficiency of algorithms, showing us both the time they require to execute and the amount of memory they consume, all in relation to the size of the input data. This critical tool enables software engineers to forecast an algorithm's behavior as data volumes expand, a key factor in ensuring applications can scale effectively and operate efficiently. Understanding and applying Big O Notation is one of the reasons why software engineers are so valuable, as it directly impacts a company's ability to handle data at scale while maintaining performance, ultimately saving significant costs and resources.
Linear Search vs. Binary Search: A Code Breakdown
Diving into what might initially appear abstract, let's explore the point at which these concepts begin to crystallize and demonstrate their real-world value. This journey into understanding not only illuminates the practical applications of seemingly theoretical ideas but also underscores why software engineers command such impressive salaries. Their expertise in navigating these complexities translates directly into tangible benefits for businesses, especially in optimizing performance and efficiency at scale.
Prompt Question that you have received before for homework.
Given a sorted array of integers, write a function to search for a specific item in the array. Implement both linear search and binary search algorithms to find the item. Compare the efficiency of both methods in terms of their time complexity.
Linear Search
Linear Search involves checking each element in a list one by one until the desired element is found or the list ends. It's simple but inefficient for large datasets, with a time complexity of O(n).
function linearSearch(sortedArray, target) {
for (let index = 0; index < sortedArray.length; index++) {
if (sortedArray[index] === target) {
return index; // Target found, return its index
}
}
return -1; // Target not found
}
// Example usage
const sortedArray = [1, 3, 5, 7, 9];
const target = 7;
console.log(`Index of ${target}: ${linearSearch(sortedArray, target)}`);Explanation:
- Loop through the array: Iterate over each element in the array using a
forloop. - Compare each element with the target: Check if the current item is equal to the target.
- Return index if found: If the current item matches the target, return the current index.
- Return -1 if not found: If the loop completes without finding the target, return -1 to indicate the target is not in the array.
Efficiency: Linear search has a time complexity of O(n), where n is the number of elements in the array. This means its performance degrades linearly as the size of the array increases.
Binary Search
Binary Search, on the other hand, is much more efficient for sorted data, cutting the search area in half with each step. It has a time complexity of O(log n).
function binarySearch(sortedArray, target) {
let left = 0;
let right = sortedArray.length - 1;
while (left <= right) {
const mid = Math.floor((left + right) / 2);
if (sortedArray[mid] === target) {
return mid; // Target found, return its index
} else if (sortedArray[mid] < target) {
left = mid + 1; // Search in the right half
} else {
right = mid - 1; // Search in the left half
}
}
return -1; // Target not found
}
// Example usage
const sortedArray = [1, 3, 5, 7, 9];
const target = 7;
console.log(`Index of ${target}: ${binarySearch(sortedArray, target)}`);Explanation:
- Initialize search boundaries: Set
leftto 0 andrightto the last index of the array. - Loop until boundaries meet: Continue searching while
leftis less than or equal toright. - Find the middle element: Calculate the middle index and compare the middle element with the target.
-
Narrow down the search:
- If the middle element is the target, return its index.
- If the target is greater than the middle element, move the
leftboundary tomid + 1to search the right half. - If the target is less than the middle element, move the
rightboundary tomid - 1to search the left half.
- Return -1 if not found: If the search boundaries cross, the target is not in the array.
Efficiency: Binary search has a time complexity of O(log n), making it much more efficient than linear search for large arrays. This is because it halves the search area with each step, significantly reducing the number of comparisons needed to find the target or determine its absence.
When dealing with large datasets, the efficiency of the search algorithm becomes critically important. Linear search and binary search represent two ends of the spectrum in terms of efficiency, especially as the size of the dataset increases.
Explanation
- Linear Search: In the worst case, linear search requires scanning each element in the dataset until it finds the target. Its time complexity is O(n), meaning the time it takes to find an item (or conclude it's not present) grows linearly with the size of the dataset. For very large datasets, this can become impractical.
- Binary Search: Binary search, on the other hand, is much more efficient for large datasets, with a time complexity of O(log n). This means that each step cuts the search area in half, drastically reducing the number of comparisons needed to find the target or determine its absence. For large datasets, binary search can significantly speed up the search process.
Comparative Analysis
Let's compare the maximum number of comparisons needed for both linear search and binary search across different dataset sizes. This will illustrate how binary search becomes increasingly advantageous as the dataset size grows.
| Dataset Size | Linear Search Max Comparisons | Binary Search Max Comparisons (Rounded Up) |
|---|---|---|
| 1 | 1 | 1 |
| 7 | 7 | 3 |
| 25 | 25 | 5 |
| 50 | 50 | 6 |
| 100 | 100 | 7 |
| 300 | 300 | 9 |
| 1,000 | 1,000 | 10 |
| 10,000 | 10,000 | 14 |
| 50,000 | 50,000 | 16 |
| 100,000 | 100,000 | 17 |
| 200,000 | 200,000 | 18 |
| 10,000,000 | 10,000,000 | 24 |
The binary search max comparisons are calculated using the formula log2(n) and then rounding up to the nearest whole number, where n is the dataset size. This demonstrates the efficiency of binary search compared to linear search, especially as the dataset size increases.
The table clearly shows that while the number of comparisons for linear search scales directly with the size of the dataset, the number of comparisons for binary search grows much more slowly. For a dataset of 10 million items, linear search could require up to 10 million comparisons, whereas binary search would only need around 24 comparisons in the worst case. This difference becomes even more pronounced with larger datasets, making binary search an essential tool for searching in large datasets efficiently.
Real-World Example: Searching in Blob Storage
Imagine a software engineer tasked with creating a search algorithm to look through blob storage. The requirement is to open each file and check if the contents match a specific data hash. This scenario demands accessing and reading through potentially millions of files.
Using linear search, the engineer would implement a solution that sequentially opens and checks each file until the match is found. However, if the files are organized in a manner that allows for binary search (e.g., sorted by some criteria that correlates with the likelihood of a match), the engineer could significantly reduce the number of files accessed.
Cost Savings Analysis:
- Linear Search: Potentially opens every file, leading to high computational and time costs.
- Binary Search: Drastically reduces the number of files accessed, saving computational resources and time.
By choosing binary search, the engineer not only speeds up the search process but also saves the company significant resources. In a scenario where such searches are frequent, the savings from this efficiency can be immense, easily justifying the high salaries of skilled software engineers. Their ability to identify and implement the most efficient algorithm for a given problem directly translates to cost savings and improved performance for the company.
Certainly, let's delve into a thorough explanation using the corrected calculations to understand the impact of search algorithm efficiency on operational costs, particularly in the context of a company handling a massive volume of searches.
Background
A company receives 500 million page views per year, with each page view resulting in 20 searches within a database of 230 million records. The cost associated with each record accessed during a search is $0.000000000327. Given these parameters, we explore the financial implications of utilizing linear search versus binary search algorithms for handling search queries.
Linear Search Cost Analysis
Linear search, characterized by its simplicity, involves scanning each record in the database sequentially until the target record is found or the end of the database is reached. This method does not require the data to be sorted and is straightforward to implement. However, its efficiency significantly decreases as the size of the dataset increases.
- Total Searches per Year: 10 billion (derived from 500 million page views * 20 searches per view).
- Average Records Accessed per Search: Assuming the worst case, where each search could potentially access all 230 million records. For the sake of calculation, we consider an average case of accessing 115 million records per search, representing a significant portion of the database.
- Annual Cost for Linear Search: Calculating the cost involves multiplying the total number of records accessed annually (1.15 x 10^15) by the cost per record ($0.000000000327), resulting in an annual operational cost of $376,050,000.
This substantial cost underscores the inefficiency of linear search for large datasets, as the operational expenses scale linearly with the number of records accessed.
Binary Search Cost Analysis
Binary search offers a more efficient alternative, particularly for sorted datasets. By dividing the search interval in half with each step, it significantly reduces the number of records that need to be accessed to locate the target.
- Records Accessed per Search: The binary search algorithm, on average, accesses log2(230,000,000) ≈ 28 records per search, a stark contrast to the linear approach.
- Annual Cost for Binary Search: The total annual cost is calculated by multiplying the total number of records accessed annually (280 billion) by the cost per record, resulting in an annual operational cost of $91.56.
Comparative Analysis and Implications
The comparison between linear and binary search algorithms reveals a dramatic difference in operational costs. While linear search results in annual costs of $376,050,000, binary search reduces this expense to a mere $91.56. This stark contrast highlights the critical importance of algorithm selection in managing operational costs and system efficiency.
For companies dealing with large-scale data operations, the choice of search algorithm can have profound financial implications. Binary search, with its logarithmic efficiency, offers substantial savings and improved performance over linear search, which becomes impractically expensive as the dataset size increases.
Conclusion
The analysis demonstrates that employing efficient search algorithms like binary search is not merely a technical optimization but a strategic financial decision. In environments where large volumes of searches are conducted, the choice of algorithm directly impacts operational costs, user experience, and overall system performance. For the company in question, adopting binary search could lead to significant cost savings, underscoring the pivotal role of algorithm efficiency in the context of large-scale data operations.
Discussion Topic
In breakout rooms, discuss the following:
- How does the choice of algorithm affect the scalability of software applications?
- Consider the blob storage search scenario. Discuss other ways the software engineer could optimize the search process, considering factors like file organization, indexing, and the use of more advanced algorithms or data structures.
- Reflect on the broader impact of software engineering decisions on a company's bottom line. How do efficiency improvements in software development compare to other cost-saving measures within a company?
This discussion will help students appreciate the value of algorithmic thinking and efficiency, not just in terms of technical performance but also in their significant financial implications for businesses.
Lesson: Why Software Engineers Make So Much Money - React's Impact on UI Development
By the end of this portion of the lesson students will be able to:
- Explain the financial benefits of mastering React for software engineers.
- Describe the concept of separation of concerns in web development and how React offers a modern approach through component-driven development.
- Understand the virtual DOM and its impact on application performance.
- Utilize React Developer Tools for debugging and optimizing React applications.
- Apply the principles of Thinking in React to break down UIs into reusable components.
- Use the
useStatehook to manage state within React components. - Build a simple counter application in React, demonstrating dynamic UI updates.
- Recognize how React's efficient rendering and component reusability save development time and costs.
- Discuss the broader implications of React and component-driven development on the tech industry and software development practices.
Introduction
Software engineers command impressive salaries, particularly those skilled in modern web development frameworks like React. This lesson explores React's role in UI development, emphasizing component-driven development and the virtual DOM, to illustrate why understanding these concepts is financially rewarding.


Separation of Concerns in Web Development
Separation of concerns is a design principle for separating a computer program into distinct sections, such that each section addresses a separate concern. Traditionally, web development is divided into:
- HTML for structure
- CSS for presentation
- JavaScript for functionality
A Different Way of Separating Concerns: Component-Driven Development
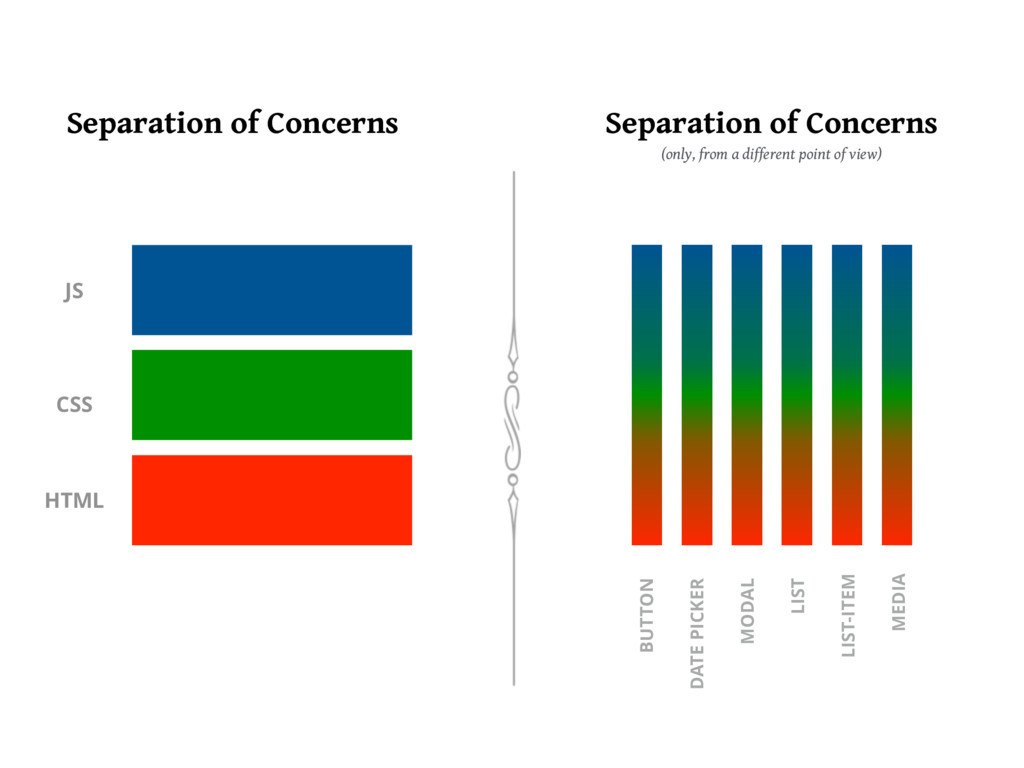
Component-Driven Development (CDD) revolutionizes UI development by using reusable components, significantly enhancing efficiency and maintainability. React, a JavaScript library by Facebook, is at the forefront of this approach, enabling developers to build interactive and dynamic web applications with ease.
Why React Saves Companies Time and Money
React's component-based architecture simplifies the development process, making UIs more scalable and maintainable. By reusing components across different parts of an application, developers can reduce development time and costs. Furthermore, React's virtual DOM optimizes rendering, making applications faster and more responsive.
The Virtual DOM Explained
Introduction to the Virtual DOM
The Virtual DOM (VDOM) is a foundational concept in modern web development, popularized by React, but also adopted by other frameworks and libraries due to its significant advantages. At its core, the Virtual DOM is an abstraction of the actual Document Object Model (DOM) used in web browsers. It is a lightweight copy of the DOM stored in memory, which React uses to optimize updates to the web page, enhancing both performance and the developer experience.
Understanding the DOM
To appreciate the benefits of the Virtual DOM, it's crucial to understand the traditional DOM, which represents the structure of a webpage. The DOM is a tree-like structure that allows JavaScript to interact with the HTML and CSS of a page, making it dynamic. However, direct manipulation of the DOM is costly in terms of performance, especially with complex applications. Each change can trigger reflows and repaints, slowing down the user experience and when MySpace and Facebook started getting exponentially larger whoever solved this problem first was going to takeover social media forever and ever and ever.
The Need for the Virtual DOM
As web applications became more dynamic and interactive, the limitations of direct DOM manipulation became apparent. Frequent updates to the DOM could lead to performance bottlenecks, negatively impacting user experience. This challenge necessitated a more efficient method of updating the UI without the overhead of direct DOM manipulation.
How the Virtual DOM Works
The Virtual DOM introduces an intermediary step between the application's state changes and the actual DOM updates. Here's a simplified overview of the process:
- Initial Render: React creates a Virtual DOM tree that corresponds to the actual DOM tree.
- State Changes: When the application's state changes, React updates the Virtual DOM instead of the real DOM.
- Diffing Algorithm: React compares the updated Virtual DOM with a pre-update version (a "snapshot").
- Determine Minimal Changes: The diffing process identifies the minimum number of changes needed to update the actual DOM.
- Batch Updates: React then updates the actual DOM in a single batch operation, minimizing reflows and repaints.
- Reconciliation: This process of updating the Virtual DOM and then syncing changes with the actual DOM is known as reconciliation.
Benefits of the Virtual DOM
Improved Performance
By minimizing direct manipulation of the actual DOM and batching updates, the Virtual DOM significantly reduces the performance cost of updates. This leads to faster rendering times and a smoother user experience, especially in complex applications.
Simplified Programming Model
The Virtual DOM abstracts away the complexities of direct DOM manipulation, allowing developers to focus on the application's state and logic. React's declarative programming model means developers describe the UI's desired state, and React handles the updates efficiently.
Below is a side-by-side comparison that showcases the complexity of direct DOM manipulation versus the simplicity and elegance of declarative React code for a similar task: updating a list based on user input.
Direct DOM Manipulation with Vanilla JavaScript
document.getElementById('addButton').addEventListener('click', function() {
var newItemText = document.getElementById('newItem').value;
if (newItemText.trim() === '') return; // Prevent adding empty items
var list = document.getElementById('itemList');
var newItem = document.createElement('li');
newItem.textContent = newItemText;
list.appendChild(newItem);
document.getElementById('newItem').value = ''; // Clear input
});HTML in a seperate file in the midst of other html:
<input type="text" id="newItem" />
<button id="addButton">Add Item</button>
<ul id="itemList"></ul>This approach requires manually creating elements, setting their properties, and appending them to the DOM. It also involves directly handling UI events and manually managing the input state. This also doesn't account for the fact that we may need to keep track of all the list items in array somewhere as well so that we can reference the data if needed.
Declarative React Code
import React, { useState } from 'react';
function ItemList() {
const [items, setItems] = useState([]);
const [newItemText, setNewItemText] = useState('');
const handleAddItem = () => {
if (!newItemText.trim()) return; // Prevent adding empty items
setItems([...items, newItemText]);
setNewItemText(''); // Clear input
};
return (
<div>
<input
type="text"
value={newItemText}
onChange={(e) => setNewItemText(e.target.value)}
/>
<button onClick={handleAddItem}>Add Item</button>
<ul>
{items.map((item, index) => (
<li key={index}>{item}</li>
))}
</ul>
</div>
);
}In the React version, the UI is described declaratively. React takes care of updating the DOM when the state changes. You simply modify the state (items and newItemText), and React automatically updates the list in the UI based on this state. This eliminates the need for direct DOM manipulation, event handling, and manual management of the input's state, showcasing the power and simplicity of React's declarative approach and this does also keep track of the list data in the items state variable.
Enhanced User Experience
Faster rendering and efficient updates contribute to a more responsive application, directly impacting user satisfaction. The Virtual DOM ensures that interactive elements and dynamic content perform well, even in resource-intensive applications.
Developer Experience
The reconciliation process, powered by the Virtual DOM, simplifies the development of complex applications. It enables hot reloading and time-travel debugging, features that significantly improve the development workflow.
The Virtual DOM in Action
Consider a dynamic application where the user interface changes frequently based on user interactions and data updates. Without the Virtual DOM, each change might require direct DOM updates, leading to sluggish performance. With the Virtual DOM, React can efficiently update the UI by only applying the necessary changes, keeping the application fast and responsive.
Applying the logic of the Virtual DOM to a complex application like Google Maps provides a fascinating case study in optimizing performance and user experience in highly interactive web applications. Google Maps, with its dynamic content, real-time updates, and intricate user interactions, exemplifies the kind of application that benefits significantly from the principles underpinning the Virtual DOM.
Challenges in Complex Web Applications
Google Maps is a web application that presents unique challenges, including:
- High Interactivity: Users frequently interact with the map, performing actions like zooming, panning, and clicking on markers.
- Dynamic Content: The application constantly updates the displayed information based on user interaction and real-time data, such as traffic conditions.
- Performance Expectations: Users expect smooth and responsive interactions, even when the application is displaying complex data sets, such as satellite imagery or street views.
The Role of the Virtual DOM in Google Maps
While Google Maps does not use React and its Virtual DOM implementation (Because Google is some playa haters), the conceptual application of a Virtual DOM-like system can illustrate how similar challenges are addressed in complex web applications.
Efficient Updates
In an application like Google Maps, the Virtual DOM's diffing algorithm would allow for minimal updates to the actual DOM. For instance, when a user pans across the map, not all elements need to be updated; only those entering the viewport require rendering. A Virtual DOM could track these changes efficiently, ensuring that only necessary updates are made, thus maintaining high performance.
Managing State Complexity
The state of Google Maps can be incredibly complex, encompassing user preferences, visible map area, zoom level, and displayed information like traffic and places. A Virtual DOM approach, with its emphasis on state management, would facilitate the organization of this complexity. By maintaining a state that represents the current view and user interactions, the application can efficiently update the UI to reflect changes, enhancing the user experience.
Incremental Rendering
For applications displaying complex data layers, such as satellite imagery or real-time traffic, incremental rendering is crucial. The Virtual DOM allows for breaking down the UI into components (or sections of the map, in this case), which can be updated independently. This means that as new data becomes available or as the user navigates the map, the application can render only the changed parts without redrawing the entire map view.
Handling User Interactions
User interactions in Google Maps, such as clicking on a place marker to get more information, can benefit from the Virtual DOM. When a user interacts with the map, the application can update the state to reflect the user's action, and the Virtual DOM can efficiently update the UI to display the requested information. This process ensures that the application remains responsive, even as it handles complex interactions and displays detailed information.
While Google Maps itself may not use React's Virtual DOM, the principles behind the Virtual DOM—efficient state management, minimal and efficient DOM updates, and component-based architecture—are universally applicable in complex web applications. These principles ensure that applications like Google Maps can handle intricate data and user interactions smoothly and responsively. The Virtual DOM's approach to web development, emphasizing efficiency and user experience, is a model for how complex applications can manage dynamic content and high interactivity without compromising on performance. This case study underscores the value of the Virtual DOM and similar strategies in building sophisticated web applications that are both powerful and user-friendly.
The Virtual DOM represents a significant advancement in web development, addressing the performance challenges of dynamic, interactive applications. By abstracting the complexity of direct DOM manipulation, React's Virtual DOM allows developers to build fast, efficient, and user-friendly web applications. This innovation not only enhances the end-user experience but also improves the development process, making it easier to build complex applications. The Virtual DOM's impact on web development is profound, offering a glimpse into the future of efficient, scalable, and responsive web application development.
React Developer Tools
React Developer Tools is a browser extension that provides a deep insight into the component trees, including component hierarchy, state, and props. It's an invaluable tool for debugging and optimizing React applications.
Thinking in React
Thinking in React is a concept developed by Facebook to help web developers build user interfaces (UI) more efficiently. It is a component-based approach that focuses on breaking down UI elements into small, reusable components. This allows developers to break down complex tasks into individual, simple parts that can be reused as needed. The main idea behind Thinking in React is to think of the UI as a set of components, or small pieces, that can be moved around, modified, and reused.
Thinking in React requires developers to break down an application into smaller components, each of which has its own state. State is data that is stored within a component, such as a user’s name or what items are in their shopping cart. By breaking down an app into smaller components, developers can more easily manage application state and make sure that updates only affect the component that needs updating.
The Thinking in React approach also encourages developers to use one-way data flow. This means that data flows from parent components to child components, rather than from child components to parent components. This helps keep components independent and makes it easier to debug and maintain an application.
Guided Code-Along: Building a Counter with React
Let's apply these concepts by building a simple counter application using React's useState hook.
Step 1: Setting Up
Ensure you have Node.js and create a new React app:
npx create-react-app react-counter
cd react-counter
npm startStep 2: Creating the Counter Component
import { useState } from "react";
export default function Counter() {
const [counter, setCounter] = useState(0);
const addOne = () => setCounter(counter + 1);
return (
<div>
<h1>{counter}</h1>
<button onClick={addOne}>Click Me to Add One</button>
</div>
);
}Explanation: This Counter component demonstrates the use of the useState hook for state management, allowing the UI to reactively update in response to user interactions.
Explanation:
- useState Hook: Initializes the counter's state with a value of 0.
useStatereturns a pair: the current state value and a function that lets you update it. - Rendering: Displays the current count and a button. Clicking the button increments the count.
- Dynamic Update: React re-renders the component with the updated state when the button is clicked, showcasing dynamic UI updates without reloading the page.
Step 3: Integrating the Counter Component
Modify App.js to include the Counter component:
import Counter from './Counter';
function App() {
return (
<div className="App">
<Counter />
</div>
);
}
export default App;That's as simple as it gets. What happens when the button is clicked.
- setCounter is passed the current value + 1
- React then compares this new value to the old value of counter
- If they are the same, React does nothing (beware of references as values when it comes to objects and arrays, make sure you understand pass by value vs pass by reference remeber the
arthurshouse taraleeshouse example from unit 1) - If they are different then React updates its VirtualDOM based on a re-render of the component and its children
- It then compares the virtualDOM to the real browser DOM and only updates the places in which they differ.
The above process is why variables that are "State" are reactive, meaning the DOM will updates when the value updates. All other variables are not reactive and will not trigger updates when changed.
NOTE: If the state is an object or array, make sure you pass a new array or object and not just modify the old one. Objects and Arrays are reference types, so if you pass the old array with modified values the references will still be equal so there will be no update to the DOM.
Example...
Don't do this
// modify the existing state
state[0] = 6
// then setState as the existing state, triggering NO update
setState(state)also don't do this
// these two variables are both pointing to the same position in memory
const updatedState = state
// no update is triggered
setState(updatedState)Do this
// create a unique copy of the array
const updatedState = [...state]
// modify the new array
updatedState[0] = 6
// set the State to the updatedArray, DOM will update
setState(updatedState)Additional Examples: Toggle Component and Form with State
After mastering the counter, consider expanding your understanding by creating a toggle component or a form that uses state to handle input values. These exercises reinforce the concept of state management and its role in creating interactive UIs.
Conclusion: The Value of React Knowledge, Big O Notation, and Component-Driven Development
Mastering React's principles, alongside a deep understanding of Big O Notation and the component-driven development approach, equips software engineers with a powerful toolkit for crafting efficient, scalable, and maintainable web applications. React's emphasis on reusable components and the virtual DOM, combined with the strategic application of Big O Notation for optimizing algorithm performance, enables developers to create highly responsive and dynamic user interfaces. This comprehensive skill set not only leads to significant cost savings and enhanced user experiences but also underscores the high market value of software engineers proficient in these areas. Through the lens of React, Big O Notation, and component-driven development, engineers are able to address complex problems with innovative solutions, thereby justifying their substantial remuneration in the tech industry.